
Qwen3-VisionCaption-2B-Thinking-GGUF
Qwen3-VisionCaption-2B-Thinking is an abliterated v1.0 variant built upon Qwen3-VL-2B-Instruct-abliterated-v1, which originates from the Qwen3-VL-2B-Instruct architecture. It is specifically optimized for seamless, high precision image captioning and uncensored visual analysis. The model is engineered for robust caption generation, deep reasoning, and unrestricted descriptive understanding across diverse visual and multimodal contexts.
Qwen3-VisionCaption-2B-Thinking [GGUF]
| File Name | Quant Type | File Size | File Link |
|---|---|---|---|
| Qwen3-VisionCaption-2B-Thinking.BF16.gguf | BF16 | 3.45 GB | Download |
| Qwen3-VisionCaption-2B-Thinking.F16.gguf | F16 | 3.45 GB | Download |
| Qwen3-VisionCaption-2B-Thinking.F32.gguf | F32 | 6.89 GB | Download |
| Qwen3-VisionCaption-2B-Thinking.Q8_0.gguf | Q8_0 | 1.83 GB | Download |
| Qwen3-VisionCaption-2B-Thinking.mmproj-bf16.gguf | mmproj-bf16 | 823 MB | Download |
| Qwen3-VisionCaption-2B-Thinking.mmproj-f16.gguf | mmproj-f16 | 819 MB | Download |
| Qwen3-VisionCaption-2B-Thinking.mmproj-f32.gguf | mmproj-f32 | 1.63 GB | Download |
| Qwen3-VisionCaption-2B-Thinking.mmproj-q8_0.gguf | mmproj-q8_0 | 445 MB | Download |
Run with llama.cpp on Jan, Ollama, LM Studio, and other platforms.
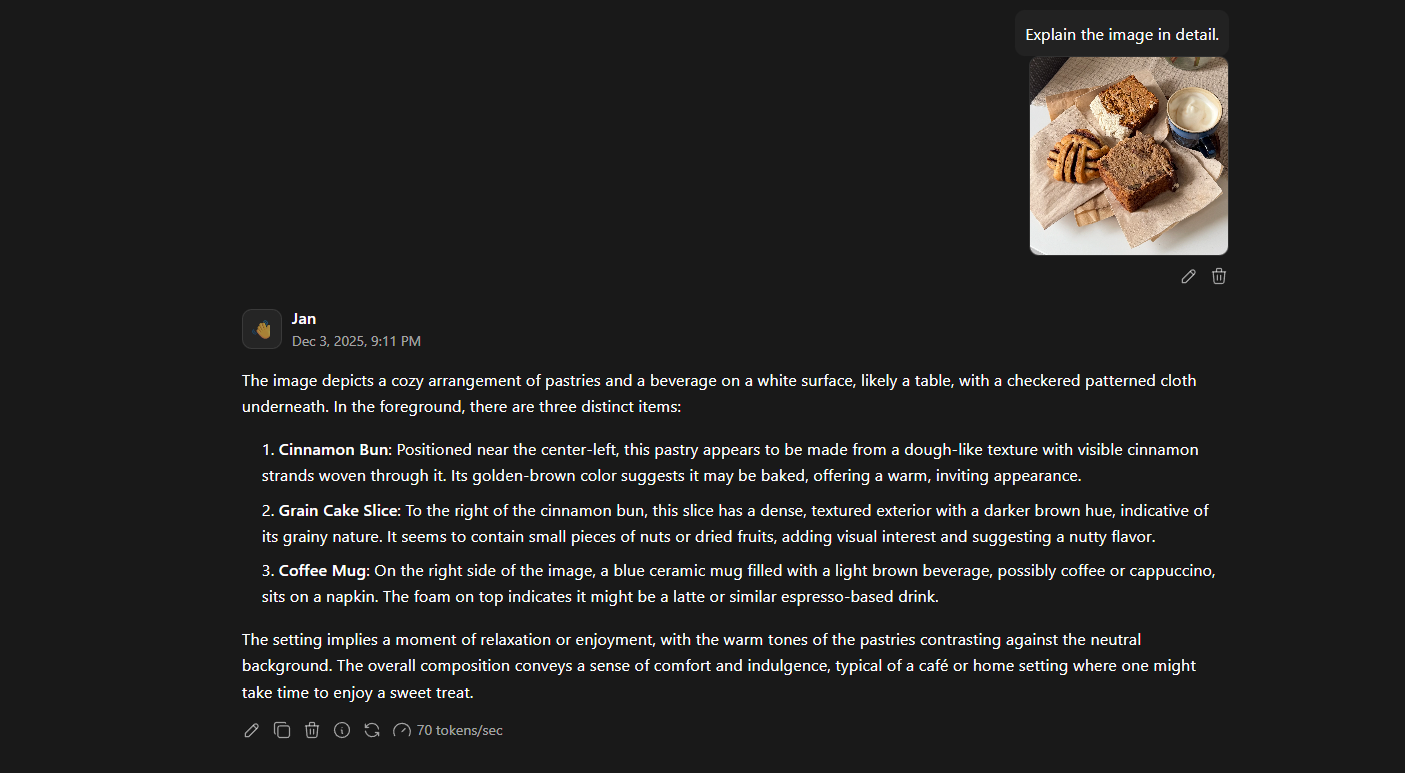
Quants Usage
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
Here is a handy graph by ikawrakow comparing some lower-quality quant types (lower is better):

- Downloads last month
- 377
Hardware compatibility
Log In
to view the estimation
8-bit
16-bit
32-bit
Model tree for prithivMLmods/Qwen3-VisionCaption-2B-Thinking-GGUF
Base model
Qwen/Qwen3-VL-2B-Thinking