Transformers documentation
PaddleOCR-VL
This model was released on 2025.10.16 and added to Hugging Face Transformers on 2025.12.10
PaddleOCR-VL
Overview
Huggingface Hub: PaddleOCR-VL | Github Repo: PaddleOCR
Official Website: Baidu AI Studio | arXiv: Technical Report
PaddleOCR-VL is a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.

Core Features
Compact yet Powerful VLM Architecture: We present a novel vision-language model that is specifically designed for resource-efficient inference, achieving outstanding performance in element recognition. By integrating a NaViT-style dynamic high-resolution visual encoder with the lightweight ERNIE-4.5-0.3B language model, we significantly enhance the model’s recognition capabilities and decoding efficiency. This integration maintains high accuracy while reducing computational demands, making it well-suited for efficient and practical document processing applications.
SOTA Performance on Document Parsing: PaddleOCR-VL achieves state-of-the-art performance in both page-level document parsing and element-level recognition. It significantly outperforms existing pipeline-based solutions and exhibiting strong competitiveness against leading vision-language models (VLMs) in document parsing. Moreover, it excels in recognizing complex document elements, such as text, tables, formulas, and charts, making it suitable for a wide range of challenging content types, including handwritten text and historical documents. This makes it highly versatile and suitable for a wide range of document types and scenarios.
Multilingual Support: PaddleOCR-VL Supports 109 languages, covering major global languages, including but not limited to Chinese, English, Japanese, Latin, and Korean, as well as languages with different scripts and structures, such as Russian (Cyrillic script), Arabic, Hindi (Devanagari script), and Thai. This broad language coverage substantially enhances the applicability of our system to multilingual and globalized document processing scenarios.
Model Architecture
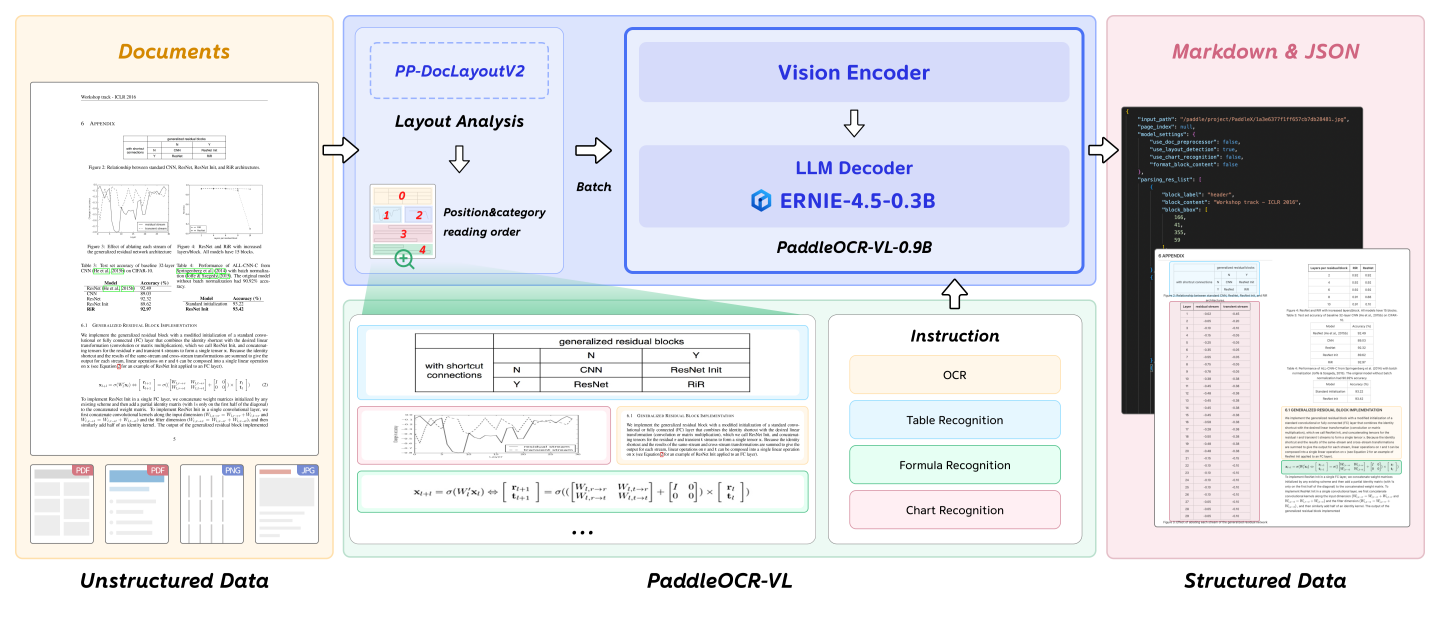
Usage
Usage tips
We currently recommend using the PaddleOCR official method for inference, as it is faster and supports page-level document parsing. The example code below only supports element-level recognition.
We have four types of element-level recognition:
- Text recognition, indicated by the prompt
OCR:. - Formula recognition, indicated by the prompt
Formula Recognition:. - Table recognition, indicated by the prompt
Table Recognition:. - Chart recognition, indicated by the prompt
Chart Recognition:.
The following examples are all based on text recognition, with the prompt OCR:.
Single input inference
The example below demonstrates how to generate text with PaddleOCRVL using Pipeline or the AutoModel.
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="PaddlePaddle/PaddleOCR-VL", dtype="bfloat16")
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/ocr_demo2.jpg"},
{"type": "text", "text": "OCR:"},
]
}
]
result = pipe(text=messages)
print(result[0]["generated_text"])Batched inference
PaddleOCRVL also supports batched inference. We advise users to use padding_side="left" when computing batched generation as it leads to more accurate results. Here is how you can do it with PaddleOCRVL using Pipeline or the AutoModel:
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="PaddlePaddle/PaddleOCR-VL", dtype="bfloat16")
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/ocr_demo2.jpg"},
{"type": "text", "text": "OCR:"},
]
}
]
result = pipe(text=[messages, messages])
print(result[0][0]["generated_text"])
print(result[1][0]["generated_text"])Using Flash Attention 2
Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the FlashAttention.
For example:
pip install flash-attn --no-build-isolation
from transformers import AutoModelForImageTextToText
model = AutoModelForImageTextToText.from_pretrained("PaddlePaddle/PaddleOCR-VL", dtype="bfloat16", attn_implementation="flash_attention_2")PaddleOCRVLForConditionalGeneration
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None pixel_values: typing.Optional[torch.Tensor] = None image_grid_thw: typing.Optional[torch.LongTensor] = None rope_deltas: typing.Optional[torch.LongTensor] = None cache_position: typing.Optional[torch.LongTensor] = None logits_to_keep: typing.Union[int, torch.Tensor] = 0 **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → transformers.models.paddleocr_vl.modeling_paddleocr_vl.PaddleOCRVLCausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - pixel_values (
torch.Tensorof shape(batch_size, num_channels, image_size, image_size), optional) — The tensors corresponding to the input images. Pixel values can be obtained using PaddleOCRVLImageProcessor. See PaddleOCRVLImageProcessor.call() for details (PaddleOCRVLProcessor uses PaddleOCRVLImageProcessor for processing images). - image_grid_thw (
torch.LongTensorof shape(num_images, 3), optional) — The temporal, height and width of feature shape of each image in LLM. - rope_deltas (
torch.LongTensorof shape(batch_size, ), optional) — The rope index difference between sequence length and multimodal rope. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length. - logits_to_keep (
Union[int, torch.Tensor], defaults to0) — If anint, compute logits for the lastlogits_to_keeptokens. If0, calculate logits for allinput_ids(special case). Only last token logits are needed for generation, and calculating them only for that token can save memory, which becomes pretty significant for long sequences or large vocabulary size. If atorch.Tensor, must be 1D corresponding to the indices to keep in the sequence length dimension. This is useful when using packed tensor format (single dimension for batch and sequence length).
Returns
transformers.models.paddleocr_vl.modeling_paddleocr_vl.PaddleOCRVLCausalLMOutputWithPast or tuple(torch.FloatTensor)
A transformers.models.paddleocr_vl.modeling_paddleocr_vl.PaddleOCRVLCausalLMOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PaddleOCRVLConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple[torch.FloatTensor], optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple[torch.FloatTensor], optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
rope_deltas (
torch.LongTensorof shape(batch_size, ), optional) — The rope index difference between sequence length and multimodal rope.
The PaddleOCRVLForConditionalGeneration forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, PaddleOCRVLForConditionalGeneration
>>> model = PaddleOCRVLForConditionalGeneration.from_pretrained("PaddlePaddle/PaddleOCR-VL", dtype="bfloat16")
>>> processor = AutoProcessor.from_pretrained("PaddlePaddle/PaddleOCR-VL")
>>> messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/ocr_demo.jpg",
},
{"type": "text", "text": "OCR:"},
],
}
]
>>> inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
>>> # Generate
>>> generated_ids = model.generate(**inputs, max_new_tokens=1024)
>>> generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
>>> output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
>>> print(output_text)PaddleOCRVLConfig
class transformers.PaddleOCRVLConfig
< source >( text_config = None vision_config = None image_token_id = 100295 video_token_id = 100296 vision_start_token_id = 101305 vision_end_token_id = 101306 **kwargs )
Parameters
- text_config (
Union[PreTrainedConfig, dict], optional, defaults toPaddleOCRTextConfig) — The config object or dictionary of the text backbone. - vision_config (
Union[PreTrainedConfig, dict], optional, defaults toPaddleOCRVisionConfig) — The config object or dictionary of the vision backbone. - image_token_id (
int, optional, defaults to 100295) — The image token index to encode the image prompt. - video_token_id (
int, optional, defaults to 100296) — The video token index to encode the image prompt. - vision_start_token_id (
int, optional, defaults to 101305) — The token index to denote start of vision input. - vision_end_token_id (
int, optional, defaults to 101306) — The token index to denote end of vision input.
This is the configuration class to store the configuration of a PaddleOCRVLForConditionalGeneration. It is used to instantiate a PaddleOCRVL model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of PaddleOCRVL PaddlePaddle/PaddleOCR-VL.
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the documentation from PreTrainedConfig for more information.
>>> from transformers import PaddleOCRVLForConditionalGeneration, PaddleOCRVLConfig
>>> # Initializing a PaddleOCRVL style configuration
>>> configuration = PaddleOCRVLConfig()
>>> # Initializing a model from the PaddleOCRVL style configuration
>>> model = PaddleOCRVLForConditionalGeneration(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPaddleOCRVisionConfig
class transformers.PaddleOCRVisionConfig
< source >( hidden_size = 1152 intermediate_size = 4304 num_hidden_layers = 27 num_attention_heads = 16 num_channels = 3 image_size = 384 patch_size = 14 hidden_act = 'gelu_pytorch_tanh' layer_norm_eps = 1e-06 attention_dropout = 0.0 spatial_merge_size = 2 **kwargs )
Parameters
- hidden_size (
int, optional, defaults to 1152) — Dimensionality of the encoder layers and the pooler layer. - intermediate_size (
int, optional, defaults to 4304) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - num_hidden_layers (
int, optional, defaults to 27) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 16) — Number of attention heads for each attention layer in the Transformer encoder. - num_channels (
int, optional, defaults to 3) — Number of channels in the input images. - image_size (
int, optional, defaults to 384) — The size (resolution) of each image. - patch_size (
int, optional, defaults to 14) — The size (resolution) of each patch. - hidden_act (
strorfunction, optional, defaults to"gelu_pytorch_tanh") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new""quick_gelu"are supported. - layer_norm_eps (
float, optional, defaults to 1e-06) — The epsilon used by the layer normalization layers. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - spatial_merge_size (
int, optional, defaults to 2) — The size used for merging spatial dimensions.
This is the configuration class to store the configuration of a PaddleOCRVisionModel. It is used to instantiate a PaddleOCRVL vision encoder according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the vision encoder of the PaddleOCRVL PaddlePaddle/PaddleOCRVL architecture.
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the documentation from PreTrainedConfig for more information.
Example:
>>> from transformers import PaddleOCRVisionConfig, PaddleOCRVisionModel
>>> # Initializing a PaddleOCRVisionConfig with PaddlePaddle/PaddleOCR-VL style configuration
>>> configuration = PaddleOCRVisionConfig()
>>> # Initializing a PaddleOCRVisionModel (with random weights) from the PaddlePaddle/PaddleOCR-VL style configuration
>>> model = PaddleOCRVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPaddleOCRTextConfig
class transformers.PaddleOCRTextConfig
< source >( vocab_size: typing.Optional[int] = 103424 hidden_size: typing.Optional[int] = 1024 intermediate_size: typing.Optional[int] = 3072 num_hidden_layers: typing.Optional[int] = 18 num_attention_heads: typing.Optional[int] = 16 num_key_value_heads: typing.Optional[int] = 2 hidden_act: typing.Optional[str] = 'silu' max_position_embeddings: typing.Optional[int] = 131072 initializer_range: typing.Optional[float] = 0.02 rms_norm_eps: typing.Optional[int] = 1e-05 use_cache: typing.Optional[int] = True pad_token_id: typing.Optional[int] = 0 bos_token_id: typing.Optional[int] = 1 eos_token_id: typing.Optional[int] = 2 tie_word_embeddings: typing.Optional[bool] = True rope_parameters: typing.Union[transformers.modeling_rope_utils.RopeParameters, dict[str, transformers.modeling_rope_utils.RopeParameters], NoneType] = None use_bias: typing.Optional[bool] = False head_dim: typing.Optional[int] = 128 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 103424) — Vocabulary size of the Ernie 4.5 model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling PaddleOCRTextModel - hidden_size (
int, optional, defaults to 1024) — Dimension of the hidden representations. - intermediate_size (
int, optional, defaults to 3072) — Dimension of the MLP representations. - num_hidden_layers (
int, optional, defaults to 18) — Number of hidden layers in the Transformer decoder. - num_attention_heads (
int, optional, defaults to 16) — Number of attention heads for each attention layer in the Transformer decoder. - num_key_value_heads (
int, optional, defaults to 2) — This is the number of key_value heads that should be used to implement Grouped Query Attention. Ifnum_key_value_heads=num_attention_heads, the model will use Multi Head Attention (MHA), ifnum_key_value_heads=1the model will use Multi Query Attention (MQA) otherwise GQA is used. When converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed by meanpooling all the original heads within that group. For more details, check out this paper. If it is not specified, will default tonum_attention_heads. - hidden_act (
strorfunction, optional, defaults to"silu") — The non-linear activation function (function or string) in the decoder. - max_position_embeddings (
int, optional, defaults to 131072) — The maximum sequence length that this model might ever be used with. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - rms_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the rms normalization layers. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions. - pad_token_id (
int, optional, defaults to 0) — Padding token id. - bos_token_id (
int, optional, defaults to 1) — Beginning of stream token id. - eos_token_id (
int, optional, defaults to 2) — End of stream token id. - tie_word_embeddings (
bool, optional, defaults toTrue) — Whether to tie weight embeddings - rope_parameters (
RopeParameters, optional) — Dictionary containing the configuration parameters for the RoPE embeddings. The dictionary should contain a value forrope_thetaand optionally parameters used for scaling in case you want to use RoPE with longermax_position_embeddings. - use_bias (
bool, optional, defaults toFalse) — Whether to use a bias in any of the projections including mlp and attention for example. - head_dim (
int, optional, defaults to 128) — The attention head dimension. If None, it will default to hidden_size // num_attention_heads
This is the configuration class to store the configuration of a PaddleOCRTextModel. It is used to instantiate an Ernie 4.5 model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Ernie 4.5 0.3B. e.g. baidu/ERNIE-4.5-0.3B-PT
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the documentation from PreTrainedConfig for more information.
>>> from transformers import PaddleOCRTextModel, PaddleOCRTextConfig
>>> # Initializing a PaddleOCRText 0.3B style configuration
>>> configuration = PaddleOCRTextConfig()
>>> # Initializing a model from the 0.3B style configuration
>>> model = PaddleOCRTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPaddleOCRTextModel
class transformers.PaddleOCRTextModel
< source >( config: PaddleOCRTextConfig )
Parameters
- config (PaddleOCRTextConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Paddleocr Vl Text Model outputting raw hidden-states without any specific head on to.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None cache_position: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → transformers.modeling_outputs.BaseModelOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values).
Returns
transformers.modeling_outputs.BaseModelOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PaddleOCRVLConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
config.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The PaddleOCRTextModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
PaddleOCRVisionModel
forward
< source >( pixel_values: FloatTensor cu_seqlens: Tensor image_grid_thw: typing.Optional[list[typing.Union[tuple[int, int, int], list[tuple[int, int, int]]]]] = None **kwargs )
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, sequence_length, image_channels, patch_size, patch_size)) — The tensors corresponding to the input images. - cu_seqlens (
torch.Tensorof shape(num_images + 1,)) — The cumulative sequence lengths of each image or video feature. - image_grid_thw (
torch.LongTensorof shape(num_images, 3), optional) — The temporal, height and width of feature shape of each image in LLM.
PaddleOCRVLImageProcessor
class transformers.PaddleOCRVLImageProcessor
< source >( do_resize: bool = True size: typing.Optional[dict[str, int]] = None resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_normalize: bool = True image_mean: typing.Union[float, list[float], NoneType] = None image_std: typing.Union[float, list[float], NoneType] = None do_convert_rgb: bool = True min_pixels: int = 147456 max_pixels: int = 2359296 patch_size: int = 14 temporal_patch_size: int = 1 merge_size: int = 2 **kwargs )
Parameters
- do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions. - size (
dict[str, int], optional) — Size of the image after resizing.shortest_edgeandlongest_edgekeys must be present. - resample (
PILImageResampling, optional, defaults toResampling.BICUBIC) — Resampling filter to use when resizing the image. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. - image_mean (
floatorlist[float], optional) — Mean to use if normalizing the image. This is a float or list of floats for each channel in the image. - image_std (
floatorlist[float], optional) — Standard deviation to use if normalizing the image. This is a float or list of floats for each channel in the image. - do_convert_rgb (
bool, optional, defaults toTrue) — Whether to convert the image to RGB. - min_pixels (
int, optional, defaults to384 * 384) — The min pixels of the image to resize the image. - max_pixels (
int, optional, defaults to1536 * 1536) — The max pixels of the image to resize the image. - patch_size (
int, optional, defaults to 14) — The spatial patch size of the vision encoder. - temporal_patch_size (
int, optional, defaults to 1) — The temporal patch size of the vision encoder. - merge_size (
int, optional, defaults to 2) — The merge size of the vision encoder to llm encoder.
Constructs a PaddleOCRVL image processor that dynamically resizes images based on the original images.
get_number_of_image_patches
< source >( height: int width: int images_kwargs = None ) → int
A utility that returns number of image patches for a given image size.
preprocess
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']] do_resize: typing.Optional[bool] = None size: typing.Optional[dict[str, int]] = None min_pixels: typing.Optional[int] = None max_pixels: typing.Optional[int] = None resample: typing.Optional[PIL.Image.Resampling] = None do_rescale: typing.Optional[bool] = None rescale_factor: typing.Optional[float] = None do_normalize: typing.Optional[bool] = None image_mean: typing.Union[float, list[float], NoneType] = None image_std: typing.Union[float, list[float], NoneType] = None patch_size: typing.Optional[int] = None temporal_patch_size: typing.Optional[int] = None merge_size: typing.Optional[int] = None do_convert_rgb: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: typing.Optional[transformers.image_utils.ChannelDimension] = <ChannelDimension.FIRST: 'channels_first'> input_data_format: typing.Union[str, transformers.image_utils.ChannelDimension, NoneType] = None )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
dict[str, int], optional, defaults toself.size) — Size of the image after resizing. Shortest edge of the image is resized to size[“shortest_edge”], with the longest edge resized to keep the input aspect ratio. - resample (
int, optional, defaults toself.resample) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling. Only has an effect ifdo_resizeis set toTrue. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorlist[float], optional, defaults toself.image_mean) — Image mean to use for normalization. Only has an effect ifdo_normalizeis set toTrue. - image_std (
floatorlist[float], optional, defaults toself.image_std) — Image standard deviation to use for normalization. Only has an effect ifdo_normalizeis set toTrue. - min_pixels (
int, optional, defaults toself.min_pixels) — The min pixels of the image to resize the image. - max_pixels (
int, optional, defaults toself.max_pixels) — The max pixels of the image to resize the image. - patch_size (
int, optional, defaults toself.patch_size) — The spatial patch size of the vision encoder. - temporal_patch_size (
int, optional, defaults toself.temporal_patch_size) — The temporal patch size of the vision encoder. - merge_size (
int, optional, defaults toself.merge_size) — The merge size of the vision encoder to llm encoder. - do_convert_rgb (
bool, optional, defaults toself.do_convert_rgb) — Whether to convert the image to RGB. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
PaddleOCRVLImageProcessorFast
class transformers.PaddleOCRVLImageProcessorFast
< source >( do_resize: bool = True size: typing.Optional[dict[str, int]] = None resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_normalize: bool = True image_mean: typing.Union[float, list[float], NoneType] = None image_std: typing.Union[float, list[float], NoneType] = None do_convert_rgb: bool = True min_pixels: int = 147456 max_pixels: int = 2359296 patch_size: int = 14 temporal_patch_size: int = 1 merge_size: int = 2 **kwargs )
PaddleOCRVLModel
class transformers.PaddleOCRVLModel
< source >( config: PaddleOCRVLConfig )
Parameters
- config (PaddleOCRVLConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Paddleocr Vl Model outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[list[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None pixel_values: typing.Optional[torch.Tensor] = None image_grid_thw: typing.Optional[torch.LongTensor] = None rope_deltas: typing.Optional[torch.LongTensor] = None cache_position: typing.Optional[torch.LongTensor] = None **kwargs )
image_grid_thw (torch.LongTensor of shape (num_images, 3), optional):
The temporal, height and width of feature shape of each image in LLM.
rope_deltas (torch.LongTensor of shape (batch_size, ), optional):
The rope index difference between sequence length and multimodal rope.
get_image_features
< source >( pixel_values: FloatTensor image_grid_thw: typing.Optional[torch.LongTensor] = None )
Encodes images into continuous embeddings that can be forwarded to the language model.
get_placeholder_mask
< source >( input_ids: LongTensor inputs_embeds: FloatTensor image_features: FloatTensor )
Obtains multimodal placeholder mask from input_ids or inputs_embeds, and checks that the placeholder token count is
equal to the length of multimodal features. If the lengths are different, an error is raised.
get_rope_index
< source >( input_ids: typing.Optional[torch.LongTensor] = None image_grid_thw: typing.Optional[torch.LongTensor] = None video_grid_thw: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it. - image_grid_thw (
torch.LongTensorof shape(num_images, 3), optional) — The temporal, height and width of feature shape of each image in LLM. - video_grid_thw (
torch.LongTensorof shape(num_videos, 3), optional) — The temporal, height and width of feature shape of each video in LLM. - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Calculate the 3D rope index based on image and video’s temporal, height and width in LLM.
Explanation: Each embedding sequence contains vision embedding and text embedding or just contains text embedding.
For pure text embedding sequence, the rotary position embedding has no difference with modern LLMs. Examples: input_ids: [T T T T T], here T is for text. temporal position_ids: [0, 1, 2, 3, 4] height position_ids: [0, 1, 2, 3, 4] width position_ids: [0, 1, 2, 3, 4]
For vision and text embedding sequence, we calculate 3D rotary position embedding for vision part and 1D rotary position embedding for text part. Examples: Assume we have a video input with 3 temporal patches, 2 height patches and 2 width patches. input_ids: [V V V V V V V V V V V V T T T T T], here V is for vision. vision temporal position_ids: [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2] vision height position_ids: [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1] vision width position_ids: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1] text temporal position_ids: [3, 4, 5, 6, 7] text height position_ids: [3, 4, 5, 6, 7] text width position_ids: [3, 4, 5, 6, 7] Here we calculate the text start position_ids as the max vision position_ids plus 1.
get_video_features
< source >( pixel_values_videos: FloatTensor video_grid_thw: typing.Optional[torch.LongTensor] = None )
Parameters
Encodes videos into continuous embeddings that can be forwarded to the language model.
PaddleOCRVLProcessor
class transformers.PaddleOCRVLProcessor
< source >( image_processor = None tokenizer = None chat_template = None **kwargs )
Parameters
- image_processor (PaddleOCRVLImageProcessor, optional) — The image processor is a required input.
- tokenizer (
LLamaTokenizerFast, optional) — The tokenizer is a required input. - chat_template (
str, optional) — A Jinja template which will be used to convert lists of messages in a chat into a tokenizable string.
PaddleOCRVLProcessor offers all the functionalities of PaddleOCRVLImageProcessor and LLamaTokenizerFast. See the
__call__() and decode() for more information.
PaddleOCRVisionTransformer
forward
< source >( pixel_values: FloatTensor cu_seqlens: Tensor attention_mask: typing.Optional[torch.Tensor] = None image_grid_thw: typing.Optional[list[typing.Union[tuple[int, int, int], list[tuple[int, int, int]]]]] = None **kwargs )
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, sequence_length, patch_size * patch_size * image_channels)) — The tensors corresponding to the input images. - cu_seqlens (
torch.Tensorof shape(num_images + 1,)) — The cumulative sequence lengths of each image or video feature. - attention_mask (
torch.Tensor, optional) — The attention_mask used in forward function shape [batch_size X sequence_length] if not None. - image_grid_thw (
torch.LongTensorof shape(num_images, 3), optional) — The temporal, height and width of feature shape of each image in LLM.