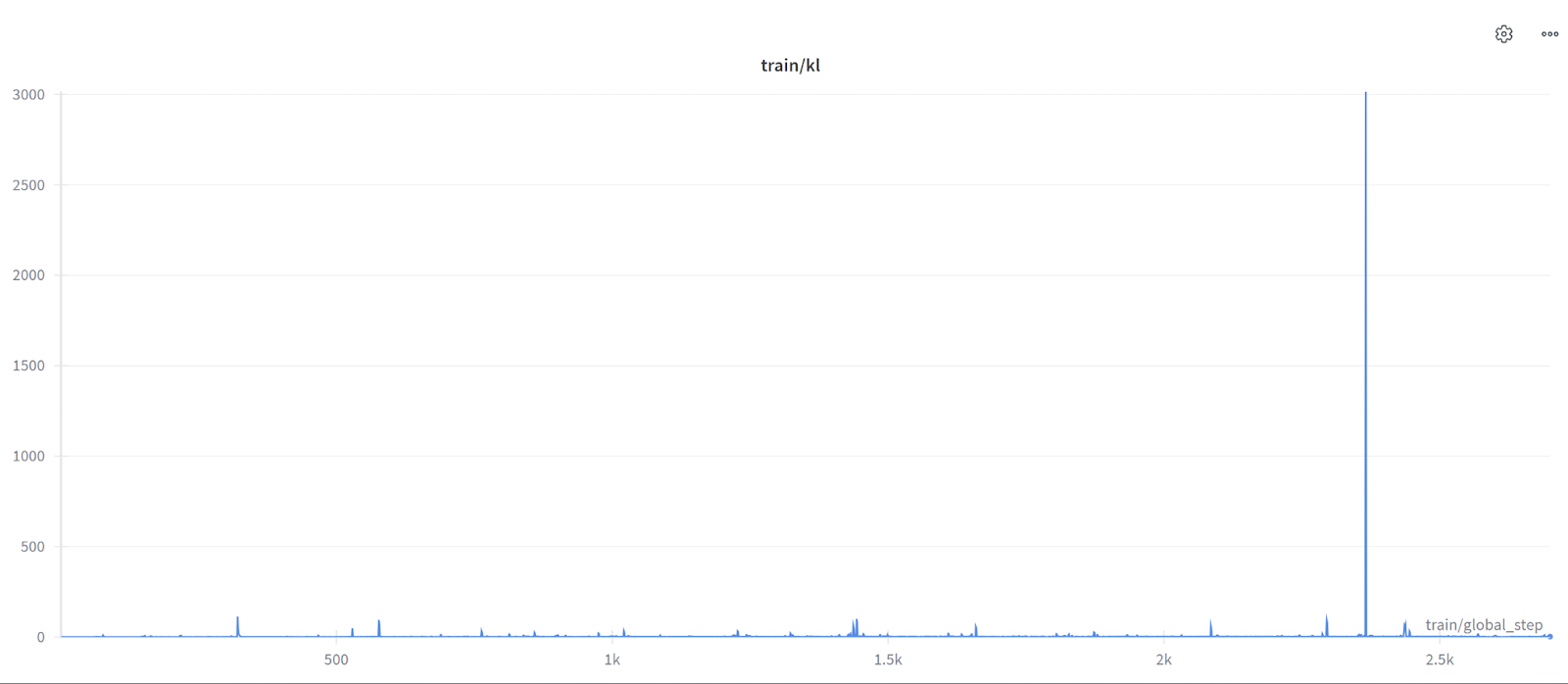
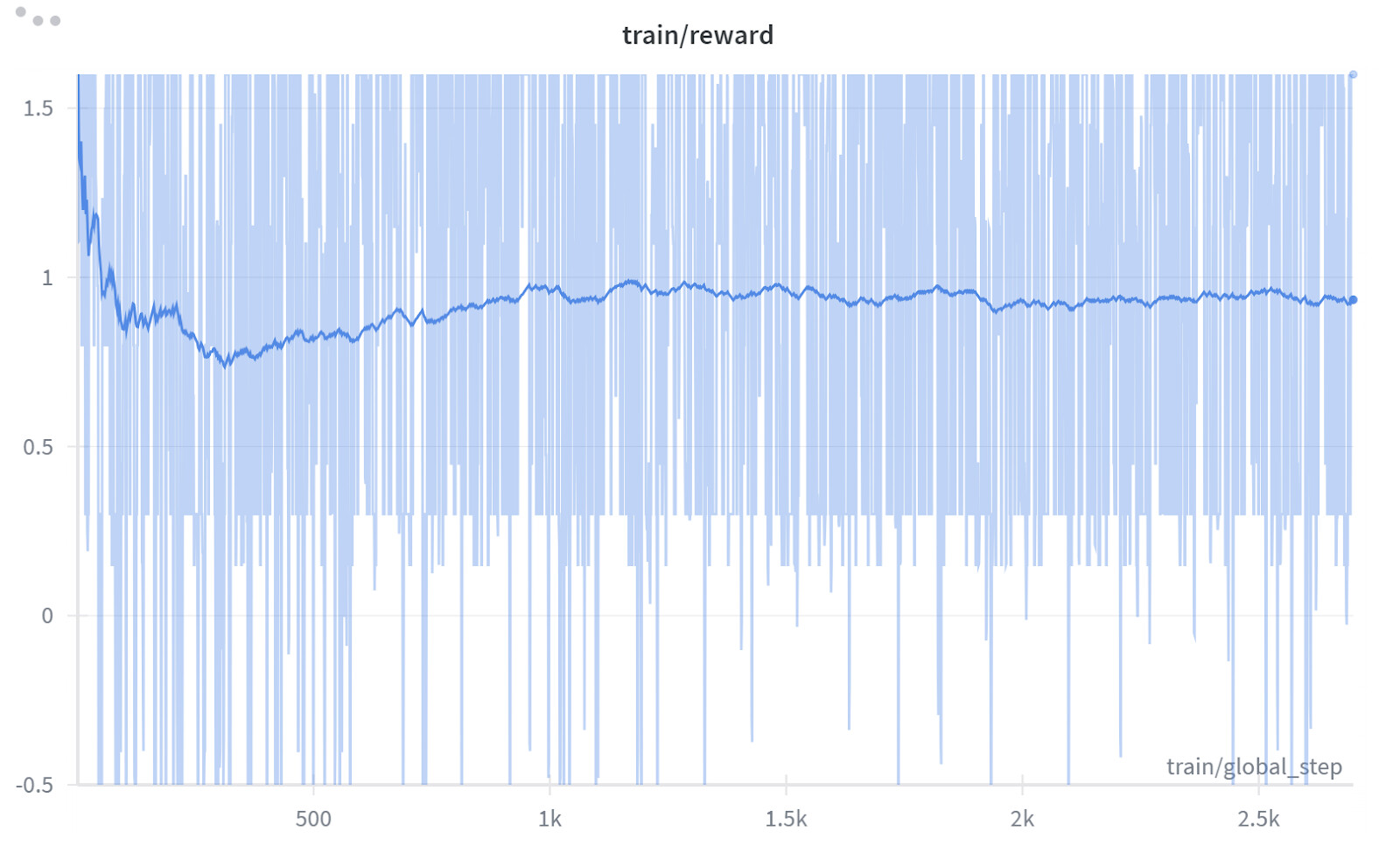
I have been working on using GRPO to train a Qwen3-4b Instruct model to (hopefully) get better at a domain-specific classification task. The reward functions focus on 3 subelements of the main classification task (i.e. if all 3 subelements are correct == yes; and otherwise == no).
My last training run, I used num_generations = 32 (but only per-device-train-batch-size of 1) in the hopes that I would create enough diversity in the responses to push the gradients when calculating the Advantage score for GRPO. However, my little model barely learned anything, and my signal was too quiet. I think the little model was a little too deterministic when only being asked to output the yes/no subelement answers. Ultimately, my trained model ended up getting slightly worse at the benchmark than the base model ![]()
Too push the gradients a bit here, are there any tips on increasing the entropy of the responses when not using a reasoning model? I was thinking of requiring the model to include a one sentence rationale of its answer, even if not graded during training, to increase token diversity, but I’m not sure if this would really be enough of a change.
Here’s a summary of the original training configs in my last failed run:
Sampling: 32 rollouts per prompt, using temperature=0.9, top_p=0.9, top_k=40.
Schedule: 2700 optimizer steps (approx. one pass over the 2700-sample subset), LR 2e-5 with a 20-step warmup, weight decay 0.01.
LoRA config: rank 16, alpha 32, dropout 0.05.