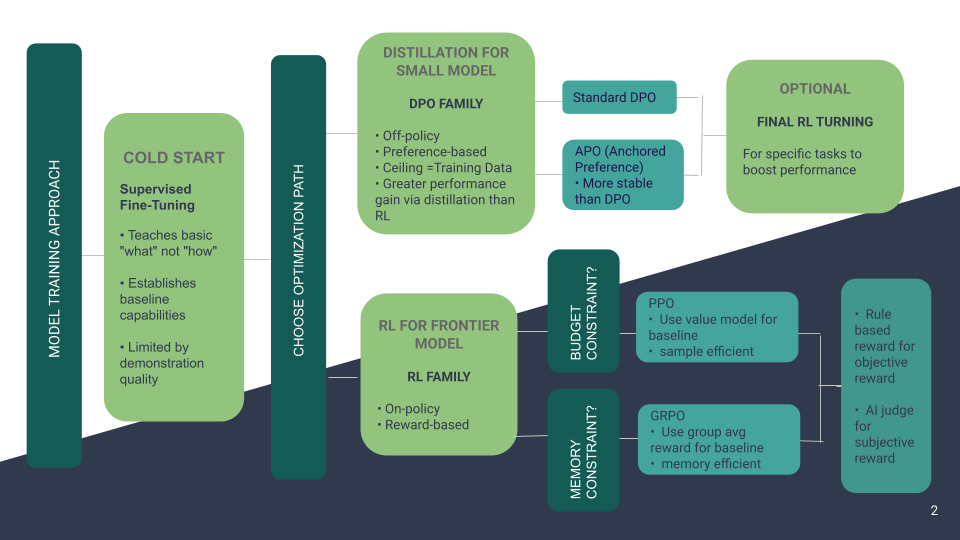
Ever wondered when to use DPO vs PPO? Or why DeepSeek-R1 chose GRPO over other RL methods?
I created this visual guide to help navigate the post-training landscape - covering distillation, reward modeling, and RL techniques with practical decision frameworks.
What’s inside:
- Decision tree for choosing between distillation (small models) vs RL (frontier models)
- When to use PPO vs GRPO (hint: memory constraints matter!)
- Reward type spectrum: rule-based vs subjective rewards
- Real examples: SmolLM3 (APO only), Tulu3 (multi-approach), DeepSeek-R1 (GRPO)
The guide synthesizes recent techniques like APO (Anchored Preference Optimization) and GRPO alongside classics like PPO and DPO, with visual frameworks to help you pick the right approach for your use case.
Free to use with attribution - perfect for talks, documentation, or just wrapping your head around this rapidly evolving space!
What post-training techniques have you found most effective? Always curious to hear what’s working in practice! ![]()