
Upload folder using huggingface_hub
Browse files- .gitattributes +3 -0
- README.md +171 -211
- chat_template.jinja +86 -0
- config.json +55 -0
- generation_config.json +11 -0
- model-00001-of-00018.safetensors +3 -0
- model-00002-of-00018.safetensors +3 -0
- model-00003-of-00018.safetensors +3 -0
- model-00004-of-00018.safetensors +3 -0
- model-00005-of-00018.safetensors +3 -0
- model-00006-of-00018.safetensors +3 -0
- model-00007-of-00018.safetensors +3 -0
- model-00008-of-00018.safetensors +3 -0
- model-00009-of-00018.safetensors +3 -0
- model-00010-of-00018.safetensors +3 -0
- model-00011-of-00018.safetensors +3 -0
- model-00012-of-00018.safetensors +3 -0
- model-00013-of-00018.safetensors +3 -0
- model-00014-of-00018.safetensors +3 -0
- model-00015-of-00018.safetensors +3 -0
- model-00016-of-00018.safetensors +3 -0
- model-00017-of-00018.safetensors +3 -0
- model-00018-of-00018.safetensors +3 -0
- model.safetensors.index.json +3 -0
- quantization_config.json +3 -0
- tokenizer.json +3 -0
- tokenizer_config.json +325 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
model.safetensors.index.json filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
quantization_config.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,257 +1,217 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
license: mit
|
| 3 |
-
base_model: zai-org/GLM-4.7
|
| 4 |
-
base_model_relation: quantized
|
| 5 |
-
quantization: exl3
|
| 6 |
pipeline_tag: text-generation
|
| 7 |
-
tags:
|
| 8 |
-
- exl3
|
| 9 |
-
library_name: exllamav3
|
| 10 |
---
|
| 11 |
|
| 12 |
-
# GLM
|
| 13 |
|
| 14 |
-
|
| 15 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
|
| 17 |
-
|
| 18 |
-
> ⚠️ Proper support for GLM-4.7 reasoning requires [PR #295 in TabbyAPI](https://github.com/theroyallab/tabbyAPI/pull/295#issuecomment-3689013998), see my modified Dockerfile.
|
| 19 |
|
| 20 |
-
|
| 21 |
-
- base quants (2, 3, 4, 5, 6, 8 bits) for Exllamav3 (using SOTA random Hadamard transforms and Trellis quantization for high-quality reconstruction)
|
| 22 |
-
- layer and tensor level KL-divergence measurements for bit-allocation optimization given a target size
|
| 23 |
-
- theoretical research related to quantization, in particular MoE quantization
|
| 24 |
|
| 25 |
-
|
|
|
|
|
|
|
|
|
|
| 26 |
|
| 27 |
-
|
| 28 |
-
- to provide the best possible quants for what is arguably the top general model of 2025
|
| 29 |
-
- to serve as a reference for quantization strategies (as of 2025 knowledge)
|
| 30 |
|
| 31 |
-
|
| 32 |
|
| 33 |
-
|
| 34 |
|
| 35 |
-
|
| 36 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
|
| 38 |
-
|
| 39 |
-
- Context: https://github.com/ModelCloud/GPTQModel/pull/2235
|
| 40 |
|
| 41 |
-

|
| 42 |
|
| 43 |
-
|
| 44 |
|
| 45 |
-
|
| 46 |
|
| 47 |
-
|
| 48 |
|
| 49 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
-
|
| 52 |
-
- Kullback-Leibler divergence (KL-div) and Top-K agreement measured through: https://github.com/turboderp-org/exllamav3/blob/v0.0.14/eval/model_diff.py
|
| 53 |
-
- Perplexity measured through: https://github.com/turboderp-org/exllamav3/blob/v0.0.14/eval/model_diff.py
|
| 54 |
-
- Caveat both quantization calibration and perplexity use the same dataset in EXL3, hence we have overfitting.\
|
| 55 |
-
The most appropriate measure for quality is KL-divergence (i.e. how well the quant reproduces the original probability distribution of token output, before samplers)\
|
| 56 |
-
For example the 3-bit quant have lower perplexity than the original FP16.\
|
| 57 |
|
| 58 |
-
|
| 59 |
-
| ---------------------------------------------------------------- | ------- | -------------------- | -------------------- | ---------- | ------ | ------ | ------ | ------ | ------ |
|
| 60 |
-
| [2bpw-H6](https://huggingface.co/mratsim/GLM-4.7-EXL3/tree/2bpw_H6) | 83 GiB | 0.65096196 | 0.75914080 | 9.36106675 | 0.7315 | 0.3852 | 0.1653 | 0.0628 | 0.0221 |
|
| 61 |
-
| [3bpw-H6](https://huggingface.co/mratsim/GLM-4.7-EXL3/tree/3bpw_H6) | 124 GiB | 0.27578034 | 0.28499938 | 6.95262863 | 0.8388 | 0.5717 | 0.3306 | 0.1713 | 0.0805 |
|
| 62 |
-
| [4bpw-H6](https://huggingface.co/mratsim/GLM-4.7-EXL3/tree/4bpw_H6) | 165 GiB | 0.13722391 | 0.13577676 | 6.60474035 | 0.8947 | 0.6948 | 0.4810 | 0.3007 | 0.1754 |
|
| 63 |
-
| [5bpw-H8](https://huggingface.co/mratsim/GLM-4.7-EXL3/tree/5bpw_H8) | 206 GiB | 0.10889671 | 0.10216227 | 6.41035355 | 0.9168 | 0.7520 | 0.5609 | 0.3905 | 0.2481 |
|
| 64 |
-
| [6bpw-H8](https://huggingface.co/mratsim/GLM-4.7-EXL3/tree/6bpw_H8) | 247 GiB | 0.08202591 | 0.0784423 | 6.32611481 | 0.9334 | 0.7951 | 0.6274 | 0.4597 | 0.3190 |
|
| 65 |
-
| [8bpw-H8](https://huggingface.co/mratsim/GLM-4.7-EXL3/tree/8bpw_H8) | 328 GiB | 0.07552261 | 0.07230427 | 6.38240525 | 0.9396 | 0.8172 | 0.6598 | 0.5048 | 0.3666 |
|
| 66 |
-
| FP16 | 656 GiB | | | 6.49784813 | | | | | |
|
| 67 |
|
| 68 |
-
|
|
|
|
|
|
|
| 69 |
|
| 70 |
-
|
| 71 |
-
> 🛈 Despite the KL-divergence, even the 2.10bpw quant looks quite smart for creative writing.\
|
| 72 |
-
> Succinct test on a scenario with 1 narrator and 6 leads.
|
| 73 |
|
| 74 |
-
|
| 75 |
-
> 🛈 HuggingFace reports file sizes in GB while VRAM is in GiB, there is a factor (1024/1000)³ = 1.0734 between both.
|
| 76 |
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
| [3.84bpw-tuned🂱](https://huggingface.co/mratsim/GLM-4.7-EXL3/tree/3.84bpw-tuned)| 158 GiB | 202752 tokens (max), k6v5 for 192GiB VRAM | 0.15823333 | 0.15401253 | 6.41935951 | 0.8854 | 0.6743 | 0.4587 | 0.2832 | 0.1638 |
|
| 81 |
|
| 82 |
-
-
|
| 83 |
-
- "tuned🂱" for hand-tuned quants
|
| 84 |
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
hf download mratsim/GLM-4.7-EXL3 --revision 3.84bpw-tuned --local-dir /path/to/your/models/directory
|
| 88 |
-
```
|
| 89 |
-
|
| 90 |
-
Unfortunately, as of December 2025 automatically optimized quants are not able to beat hand-tuned heuristics and research-based mixed-precision quantization for I suspect one of 2 reasons (or both):
|
| 91 |
-
- An optimization algorithm with no backtracking, i.e. single-pass but not comparing current layer importance with past layer importance.
|
| 92 |
-
- Not taking synergies into account. Just like LLMs have emergent properties with size, it might be that up-quantizing certain projections significantly improve KL-divergence even if it appears as noise if we only measure improvement of a single up-quant.
|
| 93 |
-
|
| 94 |
-
### Modified Dockerfile
|
| 95 |
-
|
| 96 |
-
You can build a custom tabbyAPI image that integrates PR #295:
|
| 97 |
-
|
| 98 |
-
<details>
|
| 99 |
-
<summary>Dockerfile</summary>
|
| 100 |
-
|
| 101 |
-
```Dockerfile
|
| 102 |
-
# Use an official CUDA runtime with Ubuntu as a parent image
|
| 103 |
-
FROM nvidia/cuda:12.8.1-runtime-ubuntu24.04
|
| 104 |
-
|
| 105 |
-
# Install system dependencies
|
| 106 |
-
RUN apt-get update && apt-get install -y --no-install-recommends \
|
| 107 |
-
build-essential \
|
| 108 |
-
curl \
|
| 109 |
-
ca-certificates \
|
| 110 |
-
python3.12 \
|
| 111 |
-
python3-pip \
|
| 112 |
-
python3.12-venv \
|
| 113 |
-
git \
|
| 114 |
-
&& rm -rf /var/lib/apt/lists/*
|
| 115 |
-
|
| 116 |
-
# Create a virtual environment
|
| 117 |
-
RUN python3 -m venv /opt/venv
|
| 118 |
-
|
| 119 |
-
# Activate the venv and set the PATH
|
| 120 |
-
ENV PATH="/opt/venv/bin:$PATH"
|
| 121 |
|
| 122 |
-
|
| 123 |
-
RUN pip install --no-cache-dir --upgrade pip
|
| 124 |
|
| 125 |
-
|
| 126 |
-
WORKDIR /app
|
| 127 |
|
| 128 |
-
|
| 129 |
-
RUN git clone https://github.com/theroyallab/tabbyAPI.git /app
|
| 130 |
|
| 131 |
-
# Configure git user (required for merge)
|
| 132 |
-
RUN git config --global user.email "[email protected]" && \
|
| 133 |
-
git config --global user.name "Docker Build"
|
| 134 |
|
| 135 |
-
|
| 136 |
-
RUN git fetch origin pull/295/head:pr-295 && \
|
| 137 |
-
git merge --strategy-option theirs pr-295
|
| 138 |
|
| 139 |
-
|
| 140 |
-
RUN pip install --no-cache-dir .[cu12,extras]
|
| 141 |
|
| 142 |
-
|
| 143 |
-
EXPOSE 5000
|
| 144 |
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
# Run main.py when the container launches
|
| 149 |
-
CMD ["main.py"]
|
| 150 |
```
|
| 151 |
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
### Detailed measurements of KL-div improvements
|
| 155 |
-
|
| 156 |
-
<details>
|
| 157 |
-
<summary>Quantization quality benchmarking in Exllama v3</summary>
|
| 158 |
-
Exllamav3 offers tools to measure per layer (with `-l2`) or even per-tensor (with `-l3`) contributions to KL-div improvements.
|
| 159 |
-
They might take 2 hours to 5 hours, if comparing 2 quants -- to 12 hours if comparing 3 quants -- to 24h of compute if comparing all quants.
|
| 160 |
-
|
| 161 |
-
The json file can be fed to https://github.com/turboderp-org/exllamav3/blob/v0.0.14/util/optimize.py with a target `bpw` to output an optimized quant.
|
| 162 |
-
|
| 163 |
-
Please note that from experimentations, manual tuning using the heuristics below can achieve better KL-divergence than optimizing by only mixing 3 quants and is less likely to overfit the calibration set. Having `shared experts` or `self_attn` layers use 6 or even 8-bit provide a very large improvement to KL-divergence. Even a measurement with all available quants currently doesn't achieve manual tuning results.
|
| 164 |
-
</details>
|
| 165 |
-
|
| 166 |
-
## Quantization theory and heuristics for manual tuning
|
| 167 |
-
|
| 168 |
-
<details>
|
| 169 |
-
<summary>In-depth overview of quantization theory and heuristics for manual tuning</summary>
|
| 170 |
-
|
| 171 |
-
### Layers to quantize
|
| 172 |
-
|
| 173 |
-
Quantization should be focused on Linear layers (also called Dense or Fully-Connected layers i.e. MatMul+Bias)
|
| 174 |
-
In particular quantizing LayerNorm/RMSnorm layer is strongly discouraged, see [1]
|
| 175 |
-
> LayerNorm in Quantization. Kovaleva et al. (2021); Wei et al. (2022) find that outliers in the
|
| 176 |
-
> LayerNorm parameters of BERT (Devlin et al., 2019) cause difficulties in model compression.
|
| 177 |
-
> Given the importance of LayerNorm, all the quantization methods we discuss above leave LayerNorm unquantized.
|
| 178 |
-
|
| 179 |
-
This is also reported in Intel and Nvidia repo:
|
| 180 |
-
- https://github.com/intel/neural-compressor/issues/1963#issuecomment-2274873441
|
| 181 |
-
- https://github.com/NVIDIA/TensorRT/issues/4084#issuecomment-2294513950
|
| 182 |
|
| 183 |
-
|
| 184 |
-
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
If there is enough bits, down projections should be prioritized.
|
| 188 |
-
|
| 189 |
-
According to [4]
|
| 190 |
-
> Fig. 3: Maximum absolute value over layers for a LLaMA3-8B.
|
| 191 |
-
> Each color represent a different projection and we clearly see that down_proj has the biggest
|
| 192 |
-
> spikes in input and output. We also observe that RMSNorm propagate spikes through the entire model
|
| 193 |
-
|
| 194 |
-
According to [5]
|
| 195 |
-
> Figure 5(a) illustrates the extremal ratio across layers and modules in LLaMA2-7B, highlighting
|
| 196 |
-
> that weight outliers are concentrated in the down-projection matrices Wdown
|
| 197 |
-
> ℓ of the second layer and
|
| 198 |
-
> the last two layers. Figures 5(b) and 5(c) provide detailed visualizations of these outliers in the last
|
| 199 |
-
> two layers.
|
| 200 |
-
|
| 201 |
-
### Mixture-of-Experts quantization (MoE)
|
| 202 |
-
|
| 203 |
-
Mixture-of-Experts require specific quantization techniques.
|
| 204 |
-
|
| 205 |
-
#### Mixed-precision quantization
|
| 206 |
-
|
| 207 |
-
Some layers have a higher impact on LLM performance.
|
| 208 |
-
According to [2], spending more bits in attention layers results in large gain compared to spending them in FFN layers.
|
| 209 |
-
According to [3] on 2-bit quantization:
|
| 210 |
-
- quantizing expert FFN layers do not seriously impact model quality
|
| 211 |
-
- quantizing cross-attention has some impact
|
| 212 |
-
- quantizing self-attention has a large impact
|
| 213 |
-
- quantizing dense FFN has a very significant impact
|
| 214 |
-
|
| 215 |
-
Hence to preserve model quality we should choose not to quantize dense FFN layers and self-attention layers.
|
| 216 |
-
|
| 217 |
-
We notice that:
|
| 218 |
-
- official MXFP4 weights of gpt-oss-120b from OpenAI keep self-attention in BF16:
|
| 219 |
-
- https://huggingface.co/openai/gpt-oss-120b/blob/main/model.safetensors.index.json
|
| 220 |
-
- NVFP4 weights of DeepSeek-R1 quantized by Nvidia also keep self-attention in BF16:
|
| 221 |
-
- https://huggingface.co/nvidia/DeepSeek-R1-0528-FP4/blob/main/model.safetensors.index.json
|
| 222 |
-
|
| 223 |
-
#### Layers with high-impact
|
| 224 |
-
|
| 225 |
-
According to [2], giving more bits to the first `k` blocks have a significantly higher impact on model quality than for the same last `k` blocks.
|
| 226 |
-
|
| 227 |
-
#### Expert quantization
|
| 228 |
-
|
| 229 |
-
When quantizing MoE, quantizing activations is tricky as only a subset of experts are activated per request.
|
| 230 |
|
| 231 |
-
|
| 232 |
|
| 233 |
-
|
| 234 |
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 242 |
|
| 243 |
-
|
| 244 |
-
Young Jin Kim, Raffy Fahim, Hany Hassan Awadalla\
|
| 245 |
-
https://arxiv.org/pdf/2310.02410
|
| 246 |
|
| 247 |
-
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
|
| 251 |
-
|
|
|
|
|
|
|
|
|
|
| 252 |
|
| 253 |
-
|
| 254 |
-
|
| 255 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 256 |
|
| 257 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
- zh
|
| 5 |
+
library_name: transformers
|
| 6 |
license: mit
|
|
|
|
|
|
|
|
|
|
| 7 |
pipeline_tag: text-generation
|
|
|
|
|
|
|
|
|
|
| 8 |
---
|
| 9 |
|
| 10 |
+
# GLM-4.7
|
| 11 |
|
| 12 |
+
<div align="center">
|
| 13 |
+
<img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/>
|
| 14 |
+
</div>
|
| 15 |
+
<p align="center">
|
| 16 |
+
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
|
| 17 |
+
<br>
|
| 18 |
+
📖 Check out the GLM-4.7 <a href="https://z.ai/blog/glm-4.7" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report(GLM-4.5)</a>.
|
| 19 |
+
<br>
|
| 20 |
+
📍 Use GLM-4.7 API services on <a href="https://docs.z.ai/guides/llm/glm-4.7">Z.ai API Platform. </a>
|
| 21 |
+
<br>
|
| 22 |
+
👉 One click to <a href="https://chat.z.ai">GLM-4.7</a>.
|
| 23 |
+
</p>
|
| 24 |
|
| 25 |
+
## Introduction
|
|
|
|
| 26 |
|
| 27 |
+
**GLM-4.7**, your new coding partner, is coming with the following features:
|
|
|
|
|
|
|
|
|
|
| 28 |
|
| 29 |
+
- **Core Coding**: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
|
| 30 |
+
- **Vibe Coding**: GLM-4.7 takes a big step forward in improving UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
|
| 31 |
+
- **Tool Using**: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp.
|
| 32 |
+
- **Complex Reasoning**: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
|
| 33 |
|
| 34 |
+
You can also see significant improvements in many other scenarios such as chat, creative writing, and role-play scenario.
|
|
|
|
|
|
|
| 35 |
|
| 36 |
+
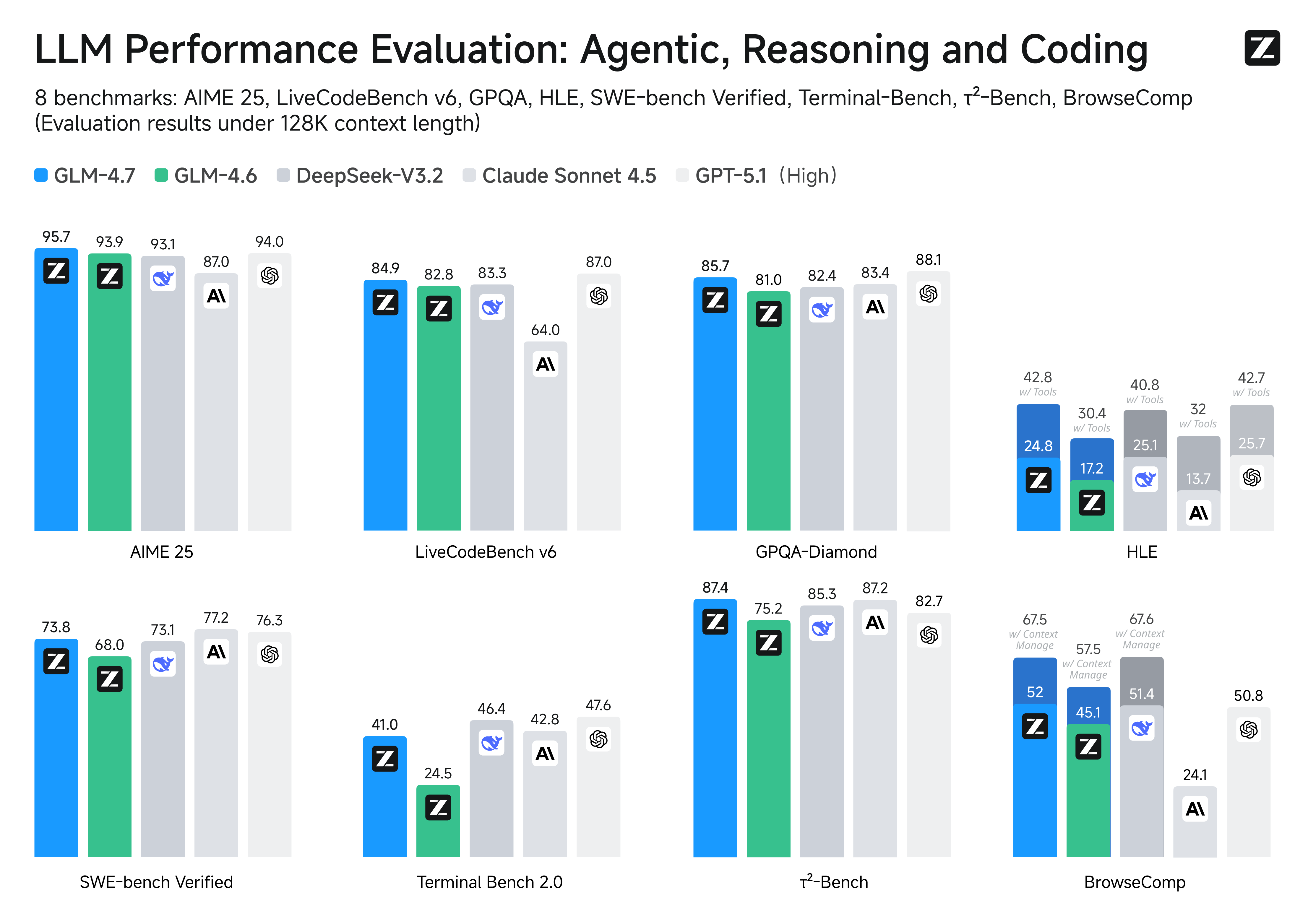
|
| 37 |
|
| 38 |
+
**Performances on Benchmarks.** More detailed comparisons of GLM-4.7 with other models GPT-5-High, GPT-5.1-High, Claude Sonnet 4.5, Gemini 3.0 Pro, DeepSeek-V3.2, Kimi K2 Thinking, on 17 benchmarks (including 8 reasoning, 5 coding, and 3 agents benchmarks) can be seen in the below table.
|
| 39 |
|
| 40 |
+
| Benchmark | GLM-4.7 | GLM-4.6 | Kimi K2 Thinking | DeepSeek-V3.2 | Gemini 3.0 Pro | Claude Sonnet 4.5 | GPT-5-High | GPT-5.1-High |
|
| 41 |
+
|:-------------------------------|:-------:|:-------:|:----------------:|:-------------:|:--------------:|:-----------------:|:----------:|:------------:|
|
| 42 |
+
| MMLU-Pro | 84.3 | 83.2 | 84.6 | 85.0 | 90.1 | 88.2 | 87.5 | 87.0 |
|
| 43 |
+
| GPQA-Diamond | 85.7 | 81.0 | 84.5 | 82.4 | 91.9 | 83.4 | 85.7 | 88.1 |
|
| 44 |
+
| HLE | 24.8 | 17.2 | 23.9 | 25.1 | 37.5 | 13.7 | 26.3 | 25.7 |
|
| 45 |
+
| HLE (w/ Tools) | 42.8 | 30.4 | 44.9 | 40.8 | 45.8 | 32.0 | 35.2 | 42.7 |
|
| 46 |
+
| AIME 2025 | 95.7 | 93.9 | 94.5 | 93.1 | 95.0 | 87.0 | 94.6 | 94.0 |
|
| 47 |
+
| HMMT Feb. 2025 | 97.1 | 89.2 | 89.4 | 92.5 | 97.5 | 79.2 | 88.3 | 96.3 |
|
| 48 |
+
| HMMT Nov. 2025 | 93.5 | 87.7 | 89.2 | 90.2 | 93.3 | 81.7 | 89.2 | - |
|
| 49 |
+
| IMOAnswerBench | 82.0 | 73.5 | 78.6 | 78.3 | 83.3 | 65.8 | 76.0 | - |
|
| 50 |
+
| LiveCodeBench-v6 | 84.9 | 82.8 | 83.1 | 83.3 | 90.7 | 64.0 | 87.0 | 87.0 |
|
| 51 |
+
| SWE-bench Verified | 73.8 | 68.0 | 71.3 | 73.1 | 76.2 | 77.2 | 74.9 | 76.3 |
|
| 52 |
+
| SWE-bench Multilingual | 66.7 | 53.8 | 61.1 | 70.2 | - | 68.0 | 55.3 | - |
|
| 53 |
+
| Terminal Bench Hard | 33.3 | 23.6 | 30.6 | 35.4 | 39.0 | 33.3 | 30.5 | 43.0 |
|
| 54 |
+
| Terminal Bench 2.0 | 41.0 | 24.5 | 35.7 | 46.4 | 54.2 | 42.8 | 35.2 | 47.6 |
|
| 55 |
+
| BrowseComp | 52.0 | 45.1 | - | 51.4 | - | 24.1 | 54.9 | 50.8 |
|
| 56 |
+
| BrowseComp (w/ Context Manage) | 67.5 | 57.5 | 60.2 | 67.6 | 59.2 | - | - | - |
|
| 57 |
+
| BrowseComp-Zh | 66.6 | 49.5 | 62.3 | 65.0 | - | 42.4 | 63.0 | - |
|
| 58 |
+
| τ²-Bench | 87.4 | 75.2 | 74.3 | 85.3 | 90.7 | 87.2 | 82.4 | 82.7 |
|
| 59 |
|
| 60 |
+
> **Coding:** AGI is a long journey, and benchmarks are only one way to evaluate performance. While the metrics provide necessary checkpoints, the most important thing is still how it *feels*. True intelligence isn't just about acing a test or processing data faster; ultimately, the success of AGI will be measured by how seamlessly it integrates into our lives-**"coding"** this time.
|
|
|
|
| 61 |
|
|
|
|
| 62 |
|
| 63 |
+
## Getting started with GLM-4.7
|
| 64 |
|
| 65 |
+
### Interleaved Thinking & Preserved Thinking
|
| 66 |
|
| 67 |
+
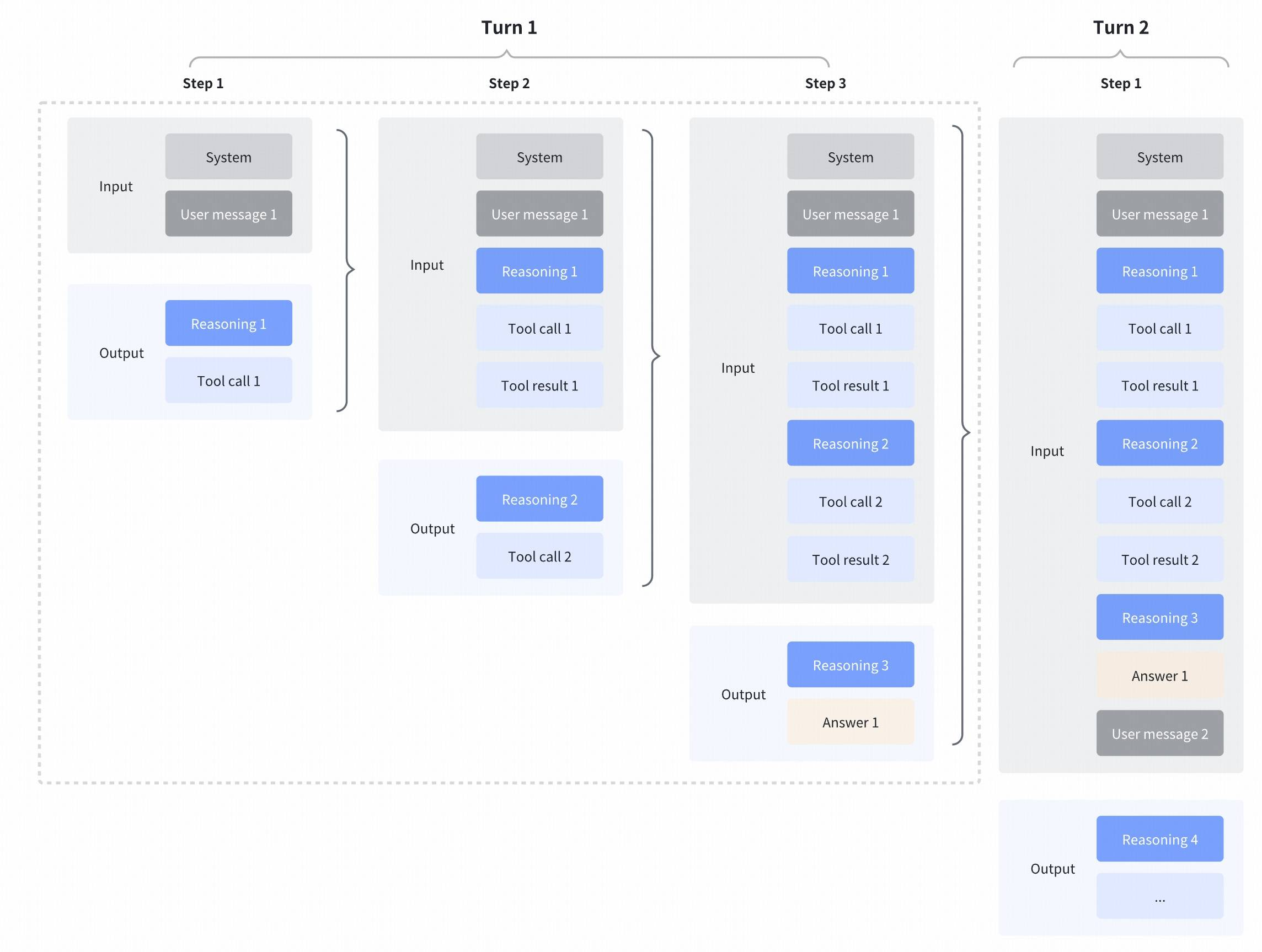
|
| 68 |
|
| 69 |
+
GLM-4.7 further enhances **Interleaved Thinking** (a feature introduced since GLM-4.5) and introduces **Preserved Thinking** and **Turn-level Thinking**. By thinking between actions and staying consistent across turns, it makes complex tasks more stable and more controllable:
|
| 70 |
+
- **Interleaved Thinking**: The model thinks before every response and tool calling, improving instruction following and the quality of generation.
|
| 71 |
+
- **Preserved Thinking**: In coding agent scenarios, the model automatically retains all thinking blocks across multi-turn conversations, reusing the existing reasoning instead of re-deriving from scratch. This reduces information loss and inconsistencies, and is well-suited for long-horizon, complex tasks.
|
| 72 |
+
- **Turn-level Thinking**: The model supports per-turn control over reasoning within a session—disable thinking for lightweight requests to reduce latency/cost, enable it for complex tasks to improve accuracy and stability.
|
| 73 |
+
|
| 74 |
+
More details: https://docs.z.ai/guides/capabilities/thinking-mode
|
| 75 |
|
| 76 |
+
### Evaluation Parameters
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 77 |
|
| 78 |
+
**Default Settings (Most Tasks)**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 79 |
|
| 80 |
+
* temperature: `1.0`
|
| 81 |
+
* top-p: `0.95`
|
| 82 |
+
* max new tokens: `131072`
|
| 83 |
|
| 84 |
+
For multi-turn agentic tasks (τ²-Bench and Terminal Bench 2), please turn on [Preserved Thinking mode](https://docs.z.ai/guides/capabilities/thinking-mode).
|
|
|
|
|
|
|
| 85 |
|
| 86 |
+
**Terminal Bench, SWE Bench Verified**
|
|
|
|
| 87 |
|
| 88 |
+
* temperature: `0.7`
|
| 89 |
+
* top-p: `1.0`
|
| 90 |
+
* max new tokens: `16384`
|
|
|
|
| 91 |
|
| 92 |
+
**τ^2-Bench**
|
|
|
|
| 93 |
|
| 94 |
+
* Temperature: `0`
|
| 95 |
+
* Max new tokens: `16384`
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 96 |
|
| 97 |
+
For τ^2-Bench evaluation, we added an additional prompt to the Retail and Telecom user interaction to avoid failure modes caused by users ending the interaction incorrectly. For the Airline domain, we applied the domain fixes as proposed in the [Claude Opus 4.5](https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf) release report.
|
|
|
|
| 98 |
|
| 99 |
+
## Serve GLM-4.7 Locally
|
|
|
|
| 100 |
|
| 101 |
+
For local deployment, GLM-4.7 supports inference frameworks including vLLM and SGLang. Comprehensive deployment instructions are available in the official [Github](https://github.com/zai-org/GLM-4.5) repository.
|
|
|
|
| 102 |
|
|
|
|
|
|
|
|
|
|
| 103 |
|
| 104 |
+
vLLM and SGLang only support GLM-4.7 on their main branches. you can use their official docker images for inference.
|
|
|
|
|
|
|
| 105 |
|
| 106 |
+
### vLLM
|
|
|
|
| 107 |
|
| 108 |
+
Using Docker as:
|
|
|
|
| 109 |
|
| 110 |
+
```shell
|
| 111 |
+
docker pull vllm/vllm-openai:nightly
|
|
|
|
|
|
|
|
|
|
| 112 |
```
|
| 113 |
|
| 114 |
+
or using pip (must use pypi.org as the index url):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 115 |
|
| 116 |
+
```shell
|
| 117 |
+
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
|
| 118 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 119 |
|
| 120 |
+
### SGLang
|
| 121 |
|
| 122 |
+
Using Docker as:
|
| 123 |
|
| 124 |
+
```shell
|
| 125 |
+
docker pull lmsysorg/sglang:dev
|
| 126 |
+
```
|
| 127 |
|
| 128 |
+
or using pip install sglang from source.
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
### transformers
|
| 132 |
+
|
| 133 |
+
using with transformers as `4.57.3` and then run:
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
import torch
|
| 137 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 138 |
+
|
| 139 |
+
MODEL_PATH = "zai-org/GLM-4.7"
|
| 140 |
+
messages = [{"role": "user", "content": "hello"}]
|
| 141 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
|
| 142 |
+
inputs = tokenizer.apply_chat_template(
|
| 143 |
+
messages,
|
| 144 |
+
tokenize=True,
|
| 145 |
+
add_generation_prompt=True,
|
| 146 |
+
return_dict=True,
|
| 147 |
+
return_tensors="pt",
|
| 148 |
+
)
|
| 149 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 150 |
+
pretrained_model_name_or_path=MODEL_PATH,
|
| 151 |
+
torch_dtype=torch.bfloat16,
|
| 152 |
+
device_map="auto",
|
| 153 |
+
)
|
| 154 |
+
inputs = inputs.to(model.device)
|
| 155 |
+
generated_ids = model.generate(**inputs, max_new_tokens=128, do_sample=False)
|
| 156 |
+
output_text = tokenizer.decode(generated_ids[0][inputs.input_ids.shape[1] :])
|
| 157 |
+
print(output_text)
|
| 158 |
+
```
|
| 159 |
|
| 160 |
+
### vLLM
|
|
|
|
|
|
|
| 161 |
|
| 162 |
+
```shell
|
| 163 |
+
vllm serve zai-org/GLM-4.7-FP8 \
|
| 164 |
+
--tensor-parallel-size 8 \
|
| 165 |
+
--tool-call-parser glm47 \
|
| 166 |
+
--reasoning-parser glm45 \
|
| 167 |
+
--enable-auto-tool-choice \
|
| 168 |
+
--served-model-name glm-4.7-fp8
|
| 169 |
+
```
|
| 170 |
|
| 171 |
+
### SGLang
|
| 172 |
+
|
| 173 |
+
```shell
|
| 174 |
+
python3 -m sglang.launch_server \
|
| 175 |
+
--model-path zai-org/GLM-4.7-FP8 \
|
| 176 |
+
--tp-size 8 \
|
| 177 |
+
--tool-call-parser glm47 \
|
| 178 |
+
--reasoning-parser glm45 \
|
| 179 |
+
--speculative-algorithm EAGLE \
|
| 180 |
+
--speculative-num-steps 3 \
|
| 181 |
+
--speculative-eagle-topk 1 \
|
| 182 |
+
--speculative-num-draft-tokens 4 \
|
| 183 |
+
--mem-fraction-static 0.8 \
|
| 184 |
+
--served-model-name glm-4.7-fp8 \
|
| 185 |
+
--host 0.0.0.0 \
|
| 186 |
+
--port 8000
|
| 187 |
+
```
|
| 188 |
|
| 189 |
+
### Parameter Instructions
|
| 190 |
+
|
| 191 |
+
- For agentic tasks of GLM-4.7, please turn on [Preserved Thinking mode](https://docs.z.ai/guides/capabilities/thinking-mode) by adding the following config (only sglang support):
|
| 192 |
+
|
| 193 |
+
```
|
| 194 |
+
"chat_template_kwargs": {
|
| 195 |
+
"enable_thinking": true,
|
| 196 |
+
"clear_thinking": false
|
| 197 |
+
}
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
- When using `vLLM` and `SGLang`, thinking mode is enabled by default when sending requests. If you want to disable the thinking switch, you need to add the `extra_body={"chat_template_kwargs": {"enable_thinking": False}}` parameter.
|
| 201 |
+
- Both support tool calling. Please use OpenAI-style tool description format for calls.
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
## Citation
|
| 205 |
+
|
| 206 |
+
If you find our work useful in your research, please consider citing the following paper:
|
| 207 |
+
|
| 208 |
+
```bibtex
|
| 209 |
+
@misc{5team2025glm45agenticreasoningcoding,
|
| 210 |
+
title={GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models},
|
| 211 |
+
author={GLM Team and Aohan Zeng and Xin Lv and Qinkai Zheng and Zhenyu Hou and Bin Chen and Chengxing Xie and Cunxiang Wang and Da Yin and Hao Zeng and Jiajie Zhang and Kedong Wang and Lucen Zhong and Mingdao Liu and Rui Lu and Shulin Cao and Xiaohan Zhang and Xuancheng Huang and Yao Wei and Yean Cheng and Yifan An and Yilin Niu and Yuanhao Wen and Yushi Bai and Zhengxiao Du and Zihan Wang and Zilin Zhu and Bohan Zhang and Bosi Wen and Bowen Wu and Bowen Xu and Can Huang and Casey Zhao and Changpeng Cai and Chao Yu and Chen Li and Chendi Ge and Chenghua Huang and Chenhui Zhang and Chenxi Xu and Chenzheng Zhu and Chuang Li and Congfeng Yin and Daoyan Lin and Dayong Yang and Dazhi Jiang and Ding Ai and Erle Zhu and Fei Wang and Gengzheng Pan and Guo Wang and Hailong Sun and Haitao Li and Haiyang Li and Haiyi Hu and Hanyu Zhang and Hao Peng and Hao Tai and Haoke Zhang and Haoran Wang and Haoyu Yang and He Liu and He Zhao and Hongwei Liu and Hongxi Yan and Huan Liu and Huilong Chen and Ji Li and Jiajing Zhao and Jiamin Ren and Jian Jiao and Jiani Zhao and Jianyang Yan and Jiaqi Wang and Jiayi Gui and Jiayue Zhao and Jie Liu and Jijie Li and Jing Li and Jing Lu and Jingsen Wang and Jingwei Yuan and Jingxuan Li and Jingzhao Du and Jinhua Du and Jinxin Liu and Junkai Zhi and Junli Gao and Ke Wang and Lekang Yang and Liang Xu and Lin Fan and Lindong Wu and Lintao Ding and Lu Wang and Man Zhang and Minghao Li and Minghuan Xu and Mingming Zhao and Mingshu Zhai and Pengfan Du and Qian Dong and Shangde Lei and Shangqing Tu and Shangtong Yang and Shaoyou Lu and Shijie Li and Shuang Li and Shuang-Li and Shuxun Yang and Sibo Yi and Tianshu Yu and Wei Tian and Weihan Wang and Wenbo Yu and Weng Lam Tam and Wenjie Liang and Wentao Liu and Xiao Wang and Xiaohan Jia and Xiaotao Gu and Xiaoying Ling and Xin Wang and Xing Fan and Xingru Pan and Xinyuan Zhang and Xinze Zhang and Xiuqing Fu and Xunkai Zhang and Yabo Xu and Yandong Wu and Yida Lu and Yidong Wang and Yilin Zhou and Yiming Pan and Ying Zhang and Yingli Wang and Yingru Li and Yinpei Su and Yipeng Geng and Yitong Zhu and Yongkun Yang and Yuhang Li and Yuhao Wu and Yujiang Li and Yunan Liu and Yunqing Wang and Yuntao Li and Yuxuan Zhang and Zezhen Liu and Zhen Yang and Zhengda Zhou and Zhongpei Qiao and Zhuoer Feng and Zhuorui Liu and Zichen Zhang and Zihan Wang and Zijun Yao and Zikang Wang and Ziqiang Liu and Ziwei Chai and Zixuan Li and Zuodong Zhao and Wenguang Chen and Jidong Zhai and Bin Xu and Minlie Huang and Hongning Wang and Juanzi Li and Yuxiao Dong and Jie Tang},
|
| 212 |
+
year={2025},
|
| 213 |
+
eprint={2508.06471},
|
| 214 |
+
archivePrefix={arXiv},
|
| 215 |
+
primaryClass={cs.CL},
|
| 216 |
+
url={https://arxiv.org/abs/2508.06471},
|
| 217 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[gMASK]<sop>
|
| 2 |
+
{%- if tools -%}
|
| 3 |
+
<|system|>
|
| 4 |
+
# Tools
|
| 5 |
+
|
| 6 |
+
You may call one or more functions to assist with the user query.
|
| 7 |
+
|
| 8 |
+
You are provided with function signatures within <tools></tools> XML tags:
|
| 9 |
+
<tools>
|
| 10 |
+
{% for tool in tools %}
|
| 11 |
+
{{ tool | tojson(ensure_ascii=False) }}
|
| 12 |
+
{% endfor %}
|
| 13 |
+
</tools>
|
| 14 |
+
|
| 15 |
+
For each function call, output the function name and arguments within the following XML format:
|
| 16 |
+
<tool_call>{function-name}<arg_key>{arg-key-1}</arg_key><arg_value>{arg-value-1}</arg_value><arg_key>{arg-key-2}</arg_key><arg_value>{arg-value-2}</arg_value>...</tool_call>{%- endif -%}
|
| 17 |
+
{%- macro visible_text(content) -%}
|
| 18 |
+
{%- if content is string -%}
|
| 19 |
+
{{- content }}
|
| 20 |
+
{%- elif content is iterable and content is not mapping -%}
|
| 21 |
+
{%- for item in content -%}
|
| 22 |
+
{%- if item is mapping and item.type == 'text' -%}
|
| 23 |
+
{{- item.text }}
|
| 24 |
+
{%- elif item is string -%}
|
| 25 |
+
{{- item }}
|
| 26 |
+
{%- endif -%}
|
| 27 |
+
{%- endfor -%}
|
| 28 |
+
{%- else -%}
|
| 29 |
+
{{- content }}
|
| 30 |
+
{%- endif -%}
|
| 31 |
+
{%- endmacro -%}
|
| 32 |
+
{%- set ns = namespace(last_user_index=-1) %}
|
| 33 |
+
{%- for m in messages %}
|
| 34 |
+
{%- if m.role == 'user' %}
|
| 35 |
+
{% set ns.last_user_index = loop.index0 -%}
|
| 36 |
+
{%- endif %}
|
| 37 |
+
{%- endfor %}
|
| 38 |
+
{% for m in messages %}
|
| 39 |
+
{%- if m.role == 'user' -%}<|user|>{{ visible_text(m.content) }}
|
| 40 |
+
{%- elif m.role == 'assistant' -%}
|
| 41 |
+
<|assistant|>
|
| 42 |
+
{%- set reasoning_content = '' %}
|
| 43 |
+
{%- set content = visible_text(m.content) %}
|
| 44 |
+
{%- if m.reasoning_content is string %}
|
| 45 |
+
{%- set reasoning_content = m.reasoning_content %}
|
| 46 |
+
{%- else %}
|
| 47 |
+
{%- if '</think>' in content %}
|
| 48 |
+
{%- set reasoning_content = content.split('</think>')[0].rstrip('\n').split('<think>')[-1].lstrip('\n') %}
|
| 49 |
+
{%- set content = content.split('</think>')[-1].lstrip('\n') %}
|
| 50 |
+
{%- endif %}
|
| 51 |
+
{%- endif %}
|
| 52 |
+
{%- if ((clear_thinking is defined and not clear_thinking) or loop.index0 > ns.last_user_index) and reasoning_content -%}
|
| 53 |
+
{{ '<think>' + reasoning_content.strip() + '</think>'}}
|
| 54 |
+
{%- else -%}
|
| 55 |
+
{{ '</think>' }}
|
| 56 |
+
{%- endif -%}
|
| 57 |
+
{%- if content.strip() -%}
|
| 58 |
+
{{ content.strip() }}
|
| 59 |
+
{%- endif -%}
|
| 60 |
+
{% if m.tool_calls %}
|
| 61 |
+
{% for tc in m.tool_calls %}
|
| 62 |
+
{%- if tc.function %}
|
| 63 |
+
{%- set tc = tc.function %}
|
| 64 |
+
{%- endif %}
|
| 65 |
+
{{- '<tool_call>' + tc.name -}}
|
| 66 |
+
{% set _args = tc.arguments %}{% for k, v in _args.items() %}<arg_key>{{ k }}</arg_key><arg_value>{{ v | tojson(ensure_ascii=False) if v is not string else v }}</arg_value>{% endfor %}</tool_call>{% endfor %}
|
| 67 |
+
{% endif %}
|
| 68 |
+
{%- elif m.role == 'tool' -%}
|
| 69 |
+
{%- if m.content is string -%}
|
| 70 |
+
{%- if loop.first or (messages[loop.index0 - 1].role != "tool") %}
|
| 71 |
+
{{- '<|observation|>' }}
|
| 72 |
+
{%- endif %}
|
| 73 |
+
{{- '<tool_response>' }}
|
| 74 |
+
{{- m.content }}
|
| 75 |
+
{{- '</tool_response>' }}
|
| 76 |
+
{%- else -%}
|
| 77 |
+
<|observation|>{% for tr in m.content %}
|
| 78 |
+
<tool_response>{{ tr.output if tr.output is defined else tr }}</tool_response>{% endfor -%}
|
| 79 |
+
{% endif -%}
|
| 80 |
+
{%- elif m.role == 'system' -%}
|
| 81 |
+
<|system|>{{ visible_text(m.content) }}
|
| 82 |
+
{%- endif -%}
|
| 83 |
+
{%- endfor -%}
|
| 84 |
+
{%- if add_generation_prompt -%}
|
| 85 |
+
<|assistant|>{{- '</think>' if (enable_thinking is defined and not enable_thinking) else '<think>' -}}
|
| 86 |
+
{%- endif -%}
|
config.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Glm4MoeForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": true,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"pad_token_id": 151329,
|
| 8 |
+
"eos_token_id": [
|
| 9 |
+
151329,
|
| 10 |
+
151336,
|
| 11 |
+
151338
|
| 12 |
+
],
|
| 13 |
+
"head_dim": 128,
|
| 14 |
+
"hidden_act": "silu",
|
| 15 |
+
"hidden_size": 5120,
|
| 16 |
+
"partial_rotary_factor": 0.5,
|
| 17 |
+
"initializer_range": 0.02,
|
| 18 |
+
"intermediate_size": 12288,
|
| 19 |
+
"max_position_embeddings": 202752,
|
| 20 |
+
"model_type": "glm4_moe",
|
| 21 |
+
"moe_intermediate_size": 1536,
|
| 22 |
+
"norm_topk_prob": true,
|
| 23 |
+
"num_attention_heads": 96,
|
| 24 |
+
"n_group": 1,
|
| 25 |
+
"topk_group": 1,
|
| 26 |
+
"n_routed_experts": 160,
|
| 27 |
+
"n_shared_experts": 1,
|
| 28 |
+
"routed_scaling_factor": 2.5,
|
| 29 |
+
"num_experts_per_tok": 8,
|
| 30 |
+
"first_k_dense_replace": 3,
|
| 31 |
+
"num_hidden_layers": 92,
|
| 32 |
+
"num_key_value_heads": 8,
|
| 33 |
+
"rms_norm_eps": 1e-05,
|
| 34 |
+
"rope_scaling": null,
|
| 35 |
+
"rope_theta": 1000000,
|
| 36 |
+
"num_nextn_predict_layers": 1,
|
| 37 |
+
"tie_word_embeddings": false,
|
| 38 |
+
"torch_dtype": "bfloat16",
|
| 39 |
+
"transformers_version": "4.54.0",
|
| 40 |
+
"use_cache": true,
|
| 41 |
+
"use_qk_norm": true,
|
| 42 |
+
"vocab_size": 151552,
|
| 43 |
+
"quantization_config": {
|
| 44 |
+
"quant_method": "exl3",
|
| 45 |
+
"version": "0.0.14",
|
| 46 |
+
"bits": 3.15,
|
| 47 |
+
"head_bits": 6,
|
| 48 |
+
"calibration": {
|
| 49 |
+
"rows": 250,
|
| 50 |
+
"cols": 2048
|
| 51 |
+
},
|
| 52 |
+
"out_scales": "auto",
|
| 53 |
+
"codebook": "mcg"
|
| 54 |
+
}
|
| 55 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"eos_token_id": [
|
| 4 |
+
151329,
|
| 5 |
+
151336,
|
| 6 |
+
151338
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 151329,
|
| 9 |
+
"temperature": 1.0,
|
| 10 |
+
"transformers_version": "4.56.2"
|
| 11 |
+
}
|
model-00001-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9a9c8d51a9a85175c1a7c3893831759cec433234e15b4dd8dcf7802d90a4a613
|
| 3 |
+
size 8459812052
|
model-00002-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0cf16f7a1d06e4bb09f704e012a087bbb56c970f659a7f9d03a27dedc728a9eb
|
| 3 |
+
size 7719707772
|
model-00003-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:52aca961fcd0a8d9ac6f6cd5a1e6a31a0dc41d463635632aa9866d5dd8d12359
|
| 3 |
+
size 7719713644
|
model-00004-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3f146584b7153de908790f2e283af290d7568793047b42a72b8d91a6848e7f7d
|
| 3 |
+
size 7719713644
|
model-00005-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:79ba0ddc4088d9d344800aa6900bc82bd66769d01a1e2618a8f2b1705003e851
|
| 3 |
+
size 7719713644
|
model-00006-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f2d892e3a12580a89f5fee04237581c4f75c63ca3e4f0ba91cb2d9b04278f23b
|
| 3 |
+
size 7719713644
|
model-00007-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f49e3495495347f6b1e14c854cfc7eaa7737ae071ea7e02659072497277be75a
|
| 3 |
+
size 7719713644
|
model-00008-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:243331b2fd913f7ce30a0197486c3bd3bdda8168f55b068296613e2feff4c36a
|
| 3 |
+
size 7719713644
|
model-00009-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f4d5538a9357e62a814c45024647c2d0b66208fcb21b4b559a3b3f9b7eb30d2c
|
| 3 |
+
size 7719713644
|
model-00010-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ddc532050d9903733c782216d6112a995834a7a7c1c86755cd73ce9ccb59957f
|
| 3 |
+
size 7719713644
|
model-00011-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8cf5ef2ff1fe9ba0d65634e3a9f121d15c4f3acc49db56e8bdfa608d2c124395
|
| 3 |
+
size 7719713644
|
model-00012-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5241c8759d51de0cdf9f0c7fe4777b8b9edd28495e0f7e06c5d1bd68d3b78fda
|
| 3 |
+
size 7719713644
|
model-00013-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eac0a5a2e0d8b84736dac43174306e8a9502447f4dfd5015e646aac5ed03e1ab
|
| 3 |
+
size 7719713644
|
model-00014-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5ebe39b5d3cef8f4b76771450a57f28ab17f081200cb40c79e6a7c8dcd23ed52
|
| 3 |
+
size 7719713644
|
model-00015-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a0cf3dd3ba1d23cf02cf9e7c5e099646304614d971a501d7d398ed8336985d71
|
| 3 |
+
size 7719713644
|
model-00016-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:93a1408adba957c564fb0e5d54d4af1ed50538e59f11c75d5fed4494b8b469ae
|
| 3 |
+
size 7719713644
|
model-00017-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c803c2326001f44a81f336fef146446bae3ea5db694f946acd0e2c594f31c1ee
|
| 3 |
+
size 7719713644
|
model-00018-of-00018.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d39f7bac0648d45b3fab88e17e2d9ef79ee5ece1c3be2968c5b5f597ea60110
|
| 3 |
+
size 8301997960
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5767e95c1f93442069f10b6c36d82e306a678bdc2b5dafbe2fa81896475633e8
|
| 3 |
+
size 16120609
|
quantization_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:72b9c137ab8a6b68e8d53bb63d92df7df198fdeb1590876c1d04602a403c59cb
|
| 3 |
+
size 53400801
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9340665016419c825c4bdabbcc9acc43b7ca2c68ce142724afa829abb1be5efd
|
| 3 |
+
size 19970699
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"151329": {
|
| 4 |
+
"content": "<|endoftext|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"151330": {
|
| 12 |
+
"content": "[MASK]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"151331": {
|
| 20 |
+
"content": "[gMASK]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"151332": {
|
| 28 |
+
"content": "[sMASK]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"151333": {
|
| 36 |
+
"content": "<sop>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"151334": {
|
| 44 |
+
"content": "<eop>",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"151335": {
|
| 52 |
+
"content": "<|system|>",
|
| 53 |
+
"lstrip": false,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
},
|
| 59 |
+
"151336": {
|
| 60 |
+
"content": "<|user|>",
|
| 61 |
+
"lstrip": false,
|
| 62 |
+
"normalized": false,
|
| 63 |
+
"rstrip": false,
|
| 64 |
+
"single_word": false,
|
| 65 |
+
"special": true
|
| 66 |
+
},
|
| 67 |
+
"151337": {
|
| 68 |
+
"content": "<|assistant|>",
|
| 69 |
+
"lstrip": false,
|
| 70 |
+
"normalized": false,
|
| 71 |
+
"rstrip": false,
|
| 72 |
+
"single_word": false,
|
| 73 |
+
"special": true
|
| 74 |
+
},
|
| 75 |
+
"151338": {
|
| 76 |
+
"content": "<|observation|>",
|
| 77 |
+
"lstrip": false,
|
| 78 |
+
"normalized": false,
|
| 79 |
+
"rstrip": false,
|
| 80 |
+
"single_word": false,
|
| 81 |
+
"special": true
|
| 82 |
+
},
|
| 83 |
+
"151339": {
|
| 84 |
+
"content": "<|begin_of_image|>",
|
| 85 |
+
"lstrip": false,
|
| 86 |
+
"normalized": false,
|
| 87 |
+
"rstrip": false,
|
| 88 |
+
"single_word": false,
|
| 89 |
+
"special": true
|
| 90 |
+
},
|
| 91 |
+
"151340": {
|
| 92 |
+
"content": "<|end_of_image|>",
|
| 93 |
+
"lstrip": false,
|
| 94 |
+
"normalized": false,
|
| 95 |
+
"rstrip": false,
|
| 96 |
+
"single_word": false,
|
| 97 |
+
"special": true
|
| 98 |
+
},
|
| 99 |
+
"151341": {
|
| 100 |
+
"content": "<|begin_of_video|>",
|
| 101 |
+
"lstrip": false,
|
| 102 |
+
"normalized": false,
|
| 103 |
+
"rstrip": false,
|
| 104 |
+
"single_word": false,
|
| 105 |
+
"special": true
|
| 106 |
+
},
|
| 107 |
+
"151342": {
|
| 108 |
+
"content": "<|end_of_video|>",
|
| 109 |
+
"lstrip": false,
|
| 110 |
+
"normalized": false,
|
| 111 |
+
"rstrip": false,
|
| 112 |
+
"single_word": false,
|
| 113 |
+
"special": true
|
| 114 |
+
},
|
| 115 |
+
"151343": {
|
| 116 |
+
"content": "<|begin_of_audio|>",
|
| 117 |
+
"lstrip": false,
|
| 118 |
+
"normalized": false,
|
| 119 |
+
"rstrip": false,
|
| 120 |
+
"single_word": false,
|
| 121 |
+
"special": true
|
| 122 |
+
},
|
| 123 |
+
"151344": {
|
| 124 |
+
"content": "<|end_of_audio|>",
|
| 125 |
+
"lstrip": false,
|
| 126 |
+
"normalized": false,
|
| 127 |
+
"rstrip": false,
|
| 128 |
+
"single_word": false,
|
| 129 |
+
"special": true
|
| 130 |
+
},
|
| 131 |
+
"151345": {
|
| 132 |
+
"content": "<|begin_of_transcription|>",
|
| 133 |
+
"lstrip": false,
|
| 134 |
+
"normalized": false,
|
| 135 |
+
"rstrip": false,
|
| 136 |
+
"single_word": false,
|
| 137 |
+
"special": true
|
| 138 |
+
},
|
| 139 |
+
"151346": {
|
| 140 |
+
"content": "<|end_of_transcription|>",
|
| 141 |
+
"lstrip": false,
|
| 142 |
+
"normalized": false,
|
| 143 |
+
"rstrip": false,
|
| 144 |
+
"single_word": false,
|
| 145 |
+
"special": true
|
| 146 |
+
},
|
| 147 |
+
"151347": {
|
| 148 |
+
"content": "<|code_prefix|>",
|
| 149 |
+
"lstrip": false,
|
| 150 |
+
"normalized": false,
|
| 151 |
+
"rstrip": false,
|
| 152 |
+
"single_word": false,
|
| 153 |
+
"special": true
|
| 154 |
+
},
|
| 155 |
+
"151348": {
|
| 156 |
+
"content": "<|code_middle|>",
|
| 157 |
+
"lstrip": false,
|
| 158 |
+
"normalized": false,
|
| 159 |
+
"rstrip": false,
|
| 160 |
+
"single_word": false,
|
| 161 |
+
"special": true
|
| 162 |
+
},
|
| 163 |
+
"151349": {
|
| 164 |
+
"content": "<|code_suffix|>",
|
| 165 |
+
"lstrip": false,
|
| 166 |
+
"normalized": false,
|
| 167 |
+
"rstrip": false,
|
| 168 |
+
"single_word": false,
|
| 169 |
+
"special": true
|
| 170 |
+
},
|
| 171 |
+
"151350": {
|
| 172 |
+
"content": "<think>",
|
| 173 |
+
"lstrip": false,
|
| 174 |
+
"normalized": false,
|
| 175 |
+
"rstrip": false,
|
| 176 |
+
"single_word": false,
|
| 177 |
+
"special": false
|
| 178 |
+
},
|
| 179 |
+
"151351": {
|
| 180 |
+
"content": "</think>",
|
| 181 |
+
"lstrip": false,
|
| 182 |
+
"normalized": false,
|
| 183 |
+
"rstrip": false,
|
| 184 |
+
"single_word": false,
|
| 185 |
+
"special": false
|
| 186 |
+
},
|
| 187 |
+
"151352": {
|
| 188 |
+
"content": "<tool_call>",
|
| 189 |
+
"lstrip": false,
|
| 190 |
+
"normalized": false,
|
| 191 |
+
"rstrip": false,
|
| 192 |
+
"single_word": false,
|
| 193 |
+
"special": false
|
| 194 |
+
},
|
| 195 |
+
"151353": {
|
| 196 |
+
"content": "</tool_call>",
|
| 197 |
+
"lstrip": false,
|
| 198 |
+
"normalized": false,
|
| 199 |
+
"rstrip": false,
|
| 200 |
+
"single_word": false,
|
| 201 |
+
"special": false
|
| 202 |
+
},
|
| 203 |
+
"151354": {
|
| 204 |
+
"content": "<tool_response>",
|
| 205 |
+
"lstrip": false,
|
| 206 |
+
"normalized": false,
|
| 207 |
+
"rstrip": false,
|
| 208 |
+
"single_word": false,
|
| 209 |
+
"special": false
|
| 210 |
+
},
|
| 211 |
+
"151355": {
|
| 212 |
+
"content": "</tool_response>",
|
| 213 |
+
"lstrip": false,
|
| 214 |
+
"normalized": false,
|
| 215 |
+
"rstrip": false,
|
| 216 |
+
"single_word": false,
|
| 217 |
+
"special": false
|
| 218 |
+
},
|
| 219 |
+
"151356": {
|
| 220 |
+
"content": "<arg_key>",
|
| 221 |
+
"lstrip": false,
|
| 222 |
+
"normalized": false,
|
| 223 |
+
"rstrip": false,
|
| 224 |
+
"single_word": false,
|
| 225 |
+
"special": false
|
| 226 |
+
},
|
| 227 |
+
"151357": {
|
| 228 |
+
"content": "</arg_key>",
|
| 229 |
+
"lstrip": false,
|
| 230 |
+
"normalized": false,
|
| 231 |
+
"rstrip": false,
|
| 232 |
+
"single_word": false,
|
| 233 |
+
"special": false
|
| 234 |
+
},
|
| 235 |
+
"151358": {
|
| 236 |
+
"content": "<arg_value>",
|
| 237 |
+
"lstrip": false,
|
| 238 |
+
"normalized": false,
|
| 239 |
+
"rstrip": false,
|
| 240 |
+
"single_word": false,
|
| 241 |
+
"special": false
|
| 242 |
+
},
|
| 243 |
+
"151359": {
|
| 244 |
+
"content": "</arg_value>",
|
| 245 |
+
"lstrip": false,
|
| 246 |
+
"normalized": false,
|
| 247 |
+
"rstrip": false,
|
| 248 |
+
"single_word": false,
|
| 249 |
+
"special": false
|
| 250 |
+
},
|
| 251 |
+
"151360": {
|
| 252 |
+
"content": "/nothink",
|
| 253 |
+
"lstrip": false,
|
| 254 |
+
"normalized": false,
|
| 255 |
+
"rstrip": false,
|
| 256 |
+
"single_word": false,
|
| 257 |
+
"special": true
|
| 258 |
+
},
|
| 259 |
+
"151361": {
|
| 260 |
+
"content": "<|begin_of_box|>",
|
| 261 |
+
"lstrip": false,
|
| 262 |
+
"normalized": false,
|
| 263 |
+
"rstrip": false,
|
| 264 |
+
"single_word": false,
|
| 265 |
+
"special": false
|
| 266 |
+
},
|
| 267 |
+
"151362": {
|
| 268 |
+
"content": "<|end_of_box|>",
|
| 269 |
+
"lstrip": false,
|
| 270 |
+
"normalized": false,
|
| 271 |
+
"rstrip": false,
|
| 272 |
+
"single_word": false,
|
| 273 |
+
"special": false
|
| 274 |
+
},
|
| 275 |
+
"151363": {
|
| 276 |
+
"content": "<|image|>",
|
| 277 |
+
"lstrip": false,
|
| 278 |
+
"normalized": false,
|
| 279 |
+
"rstrip": false,
|
| 280 |
+
"single_word": false,
|
| 281 |
+
"special": false
|
| 282 |
+
},
|
| 283 |
+
"151364": {
|
| 284 |
+
"content": "<|video|>",
|
| 285 |
+
"lstrip": false,
|
| 286 |
+
"normalized": false,
|
| 287 |
+
"rstrip": false,
|
| 288 |
+
"single_word": false,
|
| 289 |
+
"special": false
|
| 290 |
+
}
|
| 291 |
+
},
|
| 292 |
+
"additional_special_tokens": [
|
| 293 |
+
"<|endoftext|>",
|
| 294 |
+
"[MASK]",
|
| 295 |
+
"[gMASK]",
|
| 296 |
+
"[sMASK]",
|
| 297 |
+
"<sop>",
|
| 298 |
+
"<eop>",
|
| 299 |
+
"<|system|>",
|
| 300 |
+
"<|user|>",
|
| 301 |
+
"<|assistant|>",
|
| 302 |
+
"<|observation|>",
|
| 303 |
+
"<|begin_of_image|>",
|
| 304 |
+
"<|end_of_image|>",
|
| 305 |
+
"<|begin_of_video|>",
|
| 306 |
+
"<|end_of_video|>",
|
| 307 |
+
"<|begin_of_audio|>",
|
| 308 |
+
"<|end_of_audio|>",
|
| 309 |
+
"<|begin_of_transcription|>",
|
| 310 |
+
"<|end_of_transcription|>",
|
| 311 |
+
"<|code_prefix|>",
|
| 312 |
+
"<|code_middle|>",
|
| 313 |
+
"<|code_suffix|>",
|
| 314 |
+
"/nothink"
|
| 315 |
+
],
|
| 316 |
+
"clean_up_tokenization_spaces": false,
|
| 317 |
+
"do_lower_case": false,
|
| 318 |
+
"eos_token": "<|endoftext|>",
|
| 319 |
+
"extra_special_tokens": {},
|
| 320 |
+
"model_max_length": 128000,
|
| 321 |
+
"pad_token": "<|endoftext|>",
|
| 322 |
+
"padding_side": "left",
|
| 323 |
+
"remove_space": false,
|
| 324 |
+
"tokenizer_class": "PreTrainedTokenizer"
|
| 325 |
+
}
|