
honkhazard-3.1
40.6M (10.49M embed, 16L/8H) | 1.1B seen
a fourth experiment to train only on synthetic messages! very similar to honkhazard-3 but improved setup
- parameters: 40.6M (13.11 mlp, 10.49 embed, 10.49 head, 6.55 attn)
- tokens seen: 1.14B
- num_layers: 16
- num_heads: 8
- vocab_size: 32768
changes vs honkhazard-3:
- tuned LRs
- rewrote dataloader streaming so chunks are 1 unique conversation each always beginning with special tokens
- added new measurements
trained on 1x rtx 5090 in 108.8m:
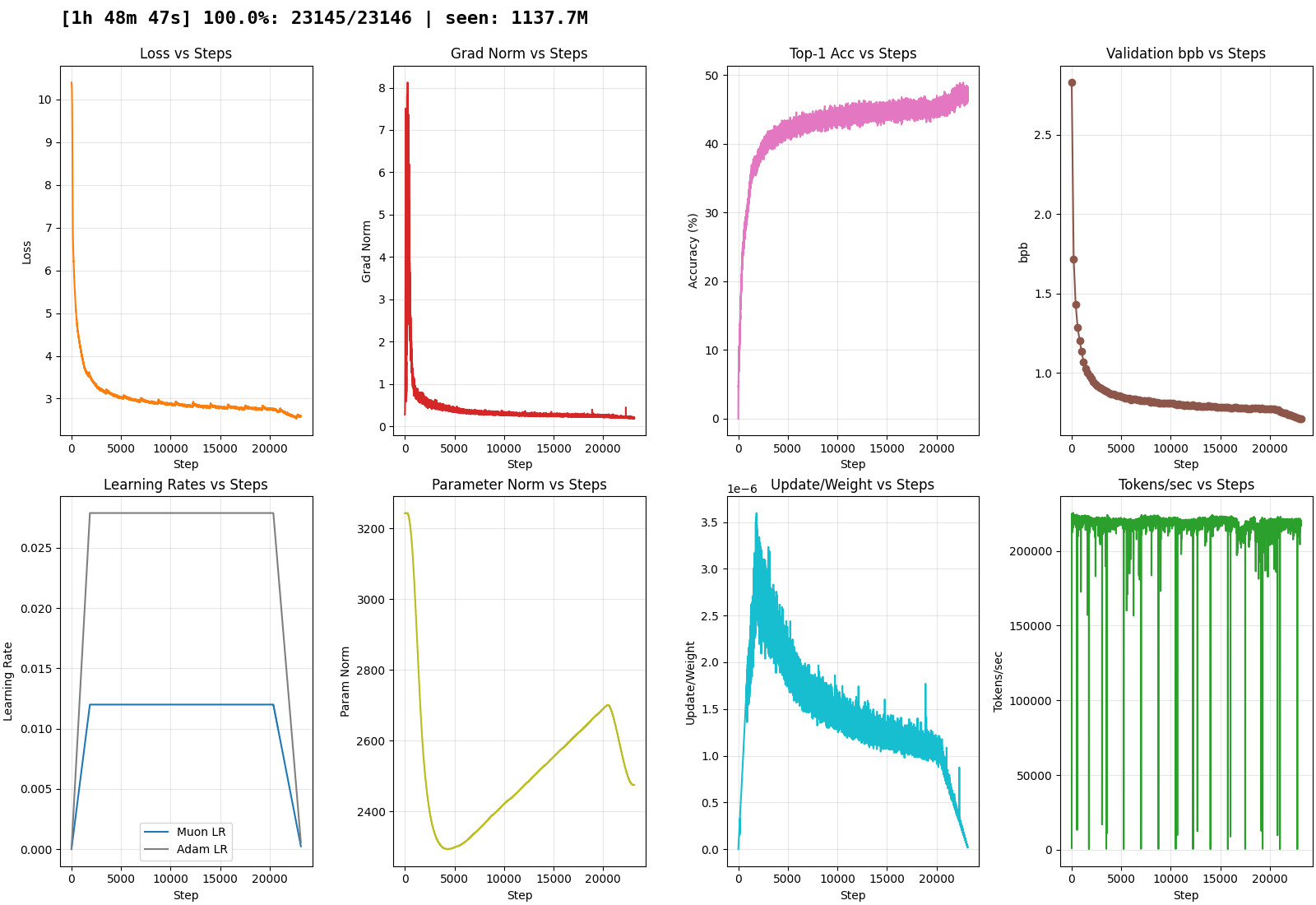
pre-training
pre-trained only on SYNTH messages in the following format:
<|bos|><|user_start|>{{query}}<|user_end|><|assistant_start|><|reasoning_start|>{{synthetic_reasoning}}<|reasoning_end|>{{synthetic_answer}}<|assistant_end|>
post-training
no post-training of any form has been performed on this model
postmortem
mostly to test infra and tune LRs. slower training due to vram limitations. seems better than honkhazard-3
final steps: 3.1:
step 23145/23146 (100.00%) | loss: 2.584534 | acc: 47.67% | grad norm: 0.1846 | lr_muon: 2.442e-04 | lr_adam: 5.675e-04 | pnorm: 2.475e+03 | upd/w: 1.795e-08 | dt: 224.51ms | tok/sec: 218,934 | tokens: 1,137,672,192 | eta: 0.00m | total time: 108.79m
Step 23146 | Validation bpb: 0.7132 | Eval time: 4.62s
3:
step 18799/18800 (99.99%) | loss: 2.613449 | grad norm: 0.1186 | lrm: 0.10 | dt: 355.98ms | tok/sec: 184,099 | total time: 129.55m
Step 18800 | Validation bpb: 0.7004
2 (* could be different run in between 2 and 3, before good infra):
step 00379/00380 (99.74%) | loss: 4.421366 | grad norm: 0.0875 | lrm: 0.12 | dt: 20393.21ms | tok/sec: 12,854 | mfu: 0.04 | total time: 126.69m
Step 00380 | Validation bpb: 1.2316
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support